*2022.06.11 기준
윈도우 환경에서 ML을 돌려야 할 필요가 생길 수 있습니다. 디스크드라이브에서 SSD로 마이그레이션 중 몇 가지 오류가 생겨 윈도우 클린설치를 하는 바람에 GPU computing 환경 또한 설정해주어야 할 필요가 생겼습니다.
지금 연구그룹에서 사용하는 제 개인 컴퓨터의 사양은 다음과 같습니다.
HP Pavilion Gaming Desktop TG01
NVIDIA Geforce RTX 3060Ti
16G RAM
Samsung Evo SSD 1000GB

CUDA 설치
CUDA 와 CuDNN 최신버전을 사용할 경우 Tensorflow 에서 지원해주지 않을 가능성이 있기 때문에, 저의 경우에는 기존에 사용하던 CUDA 11.5를 설치해주었습니다.
https://developer.nvidia.com/cuda-toolkit-archive

CUDNN 설치
v8.3.2를 설치하였습니다.
https://developer.nvidia.com/rdp/cudnn-archive

이후, 시스템 환경 변수 편집에서 Path에 들어가
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\libnvvp
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\lib
를 추가해줍니다.
Anaconda 설치 및 패키지 설치
Anaconda 최신버전을 설치해줍니다. 설치가 끝나면 업데이트를 하라고 하는데, 무슨 이유에선지 업데이트를 실행하였을 때 tensorflow에서 GPU를 인식하지 못하는 문제가 있었기 때문에 업데이트를 하지 않았습니다.
아래의 'create' 메뉴를 이용해 새로운 가상환경을 만들어줍니다. 저의 경우 ai_env 라는 이름으로, Python 버전은 3.9로 설정하였습니다.
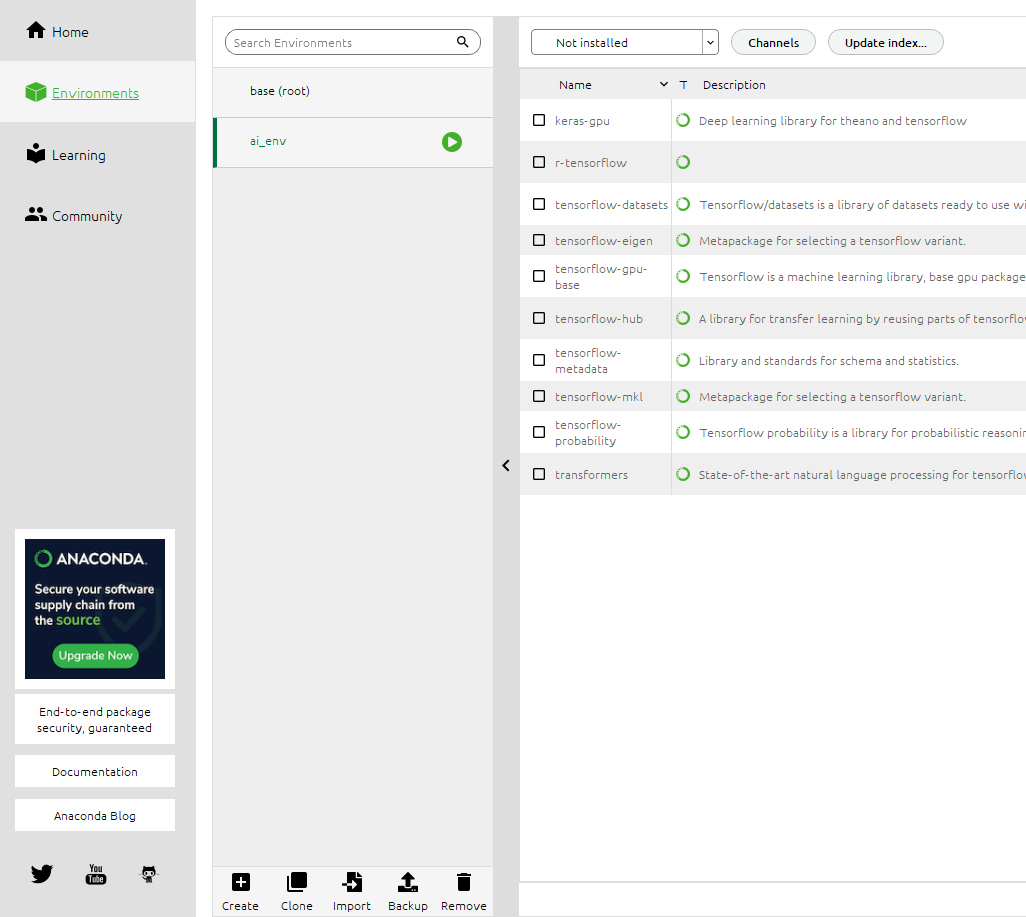
중앙 상단에서 Not Installed 드롭다운을 선택 후 tensorflow, tensorflow-gpu 를 검색해 설치해줍니다.
이후 Home 탭에서 Applications on '생성한 환경' (지금의 경우 ai_env) 를 선택하고 해당 환경에서 Jupyter Notebook을 설치해줍니다. 설치가 완료되면 윈도우에서 검색 시 다음 어플리케이션이 뜨는 것을 확인할 수 있습니다.

이후, Jupyter Notebook을 실행합니다.
GPU 확인 및 성능비교
코드상으로 tensorflow가 GPU를 인식하는지 (cuDNN이 제대로 설치되어 있다면) 확인 후, CPU대비 GPU의 성능 차이를 시간을 찍어 확인합니다.
작년 수업 때 배운 LeNet을 그대로 가져와 CPU에서 실행해보고, GPU에서도 실행해보았습니다.
import numpy as np
import tensorflow as tf
from tensorflow.python.client import device_lib
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.optimizers import Adam
print(device_lib.list_local_devices())
print("num gpus available ", len(tf.config.experimental.list_physical_devices('GPU')))
print(tf.test.is_built_with_cuda())
print(tf.version.VERSION)
print(tf.test.gpu_device_name())
# 데이터 불러오기
# 넘파이 데이터를 텐서 데이터로 변환
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 28, 28, 1)
x_test = x_test.reshape(10000, 28, 28, 1)
x_train = x_train.astype(np.float32)/255.0
x_test = x_test.astype(np.float32)/255.0
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
n_input = 784
n_hidden1 = 1024
n_hidden2 = 512
n_hidden3 = 512
n_hidden4 = 512
n_output = 10
# 레이어 설계
cnn = Sequential()
cnn.add(Conv2D(6, (5, 5), padding='same', activation='relu', input_shape=(28, 28, 1)))
cnn.add(MaxPooling2D(pool_size=(2, 2)))
cnn.add(Conv2D(16, (5, 5), padding='same', activation='relu'))
cnn.add(MaxPooling2D(pool_size=(2, 2)))
cnn.add(Conv2D(120, (5, 5), padding='same', activation='relu'))
cnn.add(Flatten())
cnn.add(Dense(84, activation='relu'))
cnn.add(Dense(10, activation='softmax'))
# 모델 컴파일
cnn.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
print("CPU를 사용한 학습")
with tf.device("/device:CPU:0"):
cnn.fit(x_train, y_train, batch_size=128, epochs=5, validation_data=(x_test, y_test), verbose=2)
print("GPU를 사용한 학습")
with tf.device("/device:GPU:0"):
cnn.fit(x_train, y_train, batch_size=128, epochs=5, validation_data=(x_test, y_test), verbose=2)
제대로 그래픽카드 디바이스드라이버, CUDA, cuDNN 이 설치되어 있다면, 모델 학습코드 이전에 다음과 유사한 메시지를 확인할 수 있습니다.
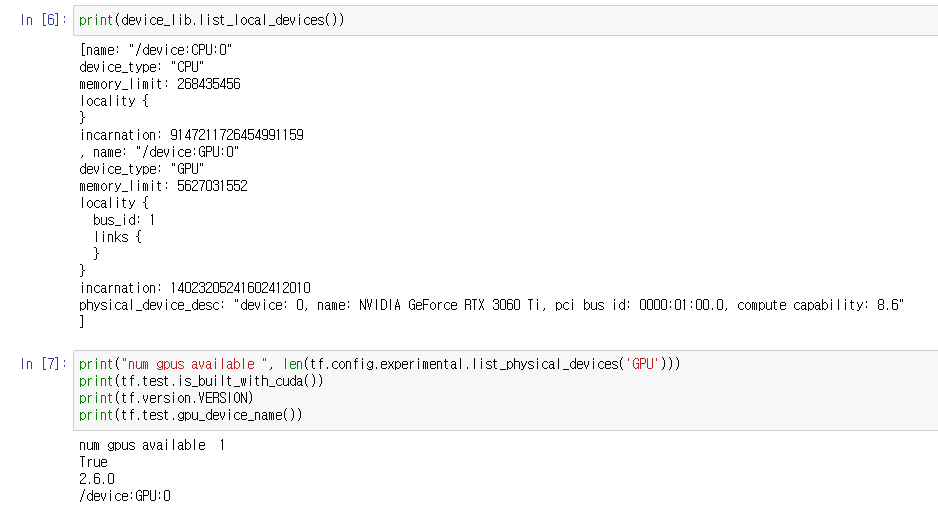
GPU를 사용해 LeNet의 학습 속도 또한 몇 배 이상 빨라졌습니다.

'CS > ML+DL' 카테고리의 다른 글
| [Principles][3]Backpropagation (0) | 2023.02.07 |
|---|---|
| [Principles][2]Mathematical Notation for Artificial Neural Networks (0) | 2023.02.06 |
| [Principles][1]Artificial Neural Network (0) | 2023.02.05 |
| PyTorch Basics(2) (0) | 2021.08.24 |
| PyTorch Basics(1) (0) | 2021.08.24 |