딥러닝의 핵심이론인 backpropagation(역전파) 알고리즘에 대한 설명입니다. 지금까지 gradient descent라는 개념을 보며 loss함수를 미분하여 그것이 minimum일 때를 찾는 과정이 learning시 accuracy를 높일 수 있는 방법이며, local minimum 등에 갇히게 되는 것이 model의 learning 성능을 저하시키는 요인이라고 배워왔습니다. 그렇다면 각 parameter를 loss가 최소화되게끔 맞춰가는 과정이 필요할텐데, neural network(NN)의 각각의 요소 (weight, bias)에 대해 어떻게 미분을 구할지를 알아보겠습니다.
아래 필기와 같은 네트워크가 있다고 가정합니다. 그렇다면 첫 layer의 weight 2*3=6개, bias 3개, 두 번째 layer의 weight 3*2=6개, bias 2개 총 17개의 parameter가 존재합니다.
Loss 라는것은 weight와 bias를 어떠한 방식으로 변경했는지에 따라 바뀝니다. 따라서 w1 ~ w12에 대한 미분과 b1 ~ b5에 대한 미분을 모두 고려해볼 필요가 있습니다. 출력단에서 입력단으로 갈수록 미분을 구하는 것이 복잡해보이는데, 계산은 복잡할 수 있으나 chain rule 이라는 간단한 원리를 이용해 해결이 가능합니다.

위 chain rule 예시에서 볼 수 있듯, NN의 parameter를 chain rule의 요소로서 활용해볼 수 있습니다. 참고로 ②의 값은 ①에서 이어져서 뒤로 타고들어가 NN앞쪽으로 미분을 더 진행하며 얻어낸 값입니다. 여기서 주의해야 할 점은 W2로 미분하지 않고 n1으로 미분하는 것입니다. n0는 0번째 layer에서의 값이라고 생각하시면 되겠습니다.

결국 learning이라는 것은, training 데이터를 통과시켜 forward propagation 하여 loss 를 구하고 값들을(필기 상 노란색으로 쓰인 값) 저장 후, backpropagation 하여 weight를 다시 구해내는 과정이라는 결론을 얻을 수 있습니다. 예시로 든 NN에서는 총 17개에 대한 미분을 위와같은 방법으로 구해볼 수 있습니다.

액웨액웨..(..?)가 뭔지 알고싶으시다면 패스트캠퍼스 혁펜하임 AI Deep Dive 수강신청!
행렬미분을 이용하여 backprop 하는 방법도 (대학원 들어가기 전에 알면 매우 큰 도움...!) 강의에 소개되어 있습니다.
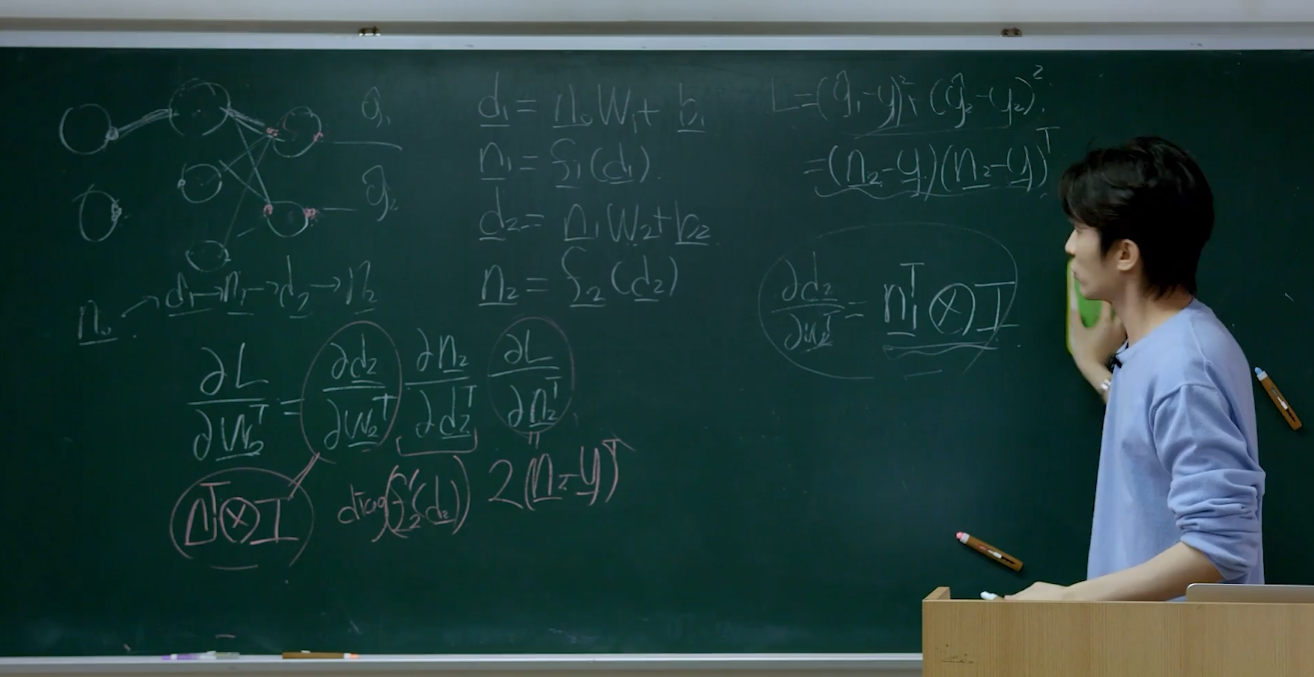

1) 본 게시글은 패스트캠퍼스 [혁펜하임의 AI DEEP DIVE] 체험단 활동을 위해 작성되었습니다.
2) 강의 링크 : https://bit.ly/3GV73FN
혁펜하임의 AI DEEP DIVE (Online.) | 패스트캠퍼스
카이스트 박사, 삼성전자 연구원 출신 인플루언서 혁펜하임과 함께하는 AI 딥러닝 강의! 필수 기초 수학 이론과 인공지능 핵심 이론을 넘어 모델 실습 리뷰까지 확장된 커리큘럼으로 기초 학습
fastcampus.co.kr
'CS > ML+DL' 카테고리의 다른 글
| [Principles][2]Mathematical Notation for Artificial Neural Networks (0) | 2023.02.06 |
|---|---|
| [Principles][1]Artificial Neural Network (0) | 2023.02.05 |
| CUDA + cuDNN + Anaconda Setup (0) | 2022.06.11 |
| PyTorch Basics(2) (0) | 2021.08.24 |
| PyTorch Basics(1) (0) | 2021.08.24 |