Image courtesy of Prof. Young Ik Eom - SKKU,
Maurice J. Bach - The design of the UNIX operating system

프로그램은 two level hierarchy 로 이루어져 있다. 안쪽을 커널이라고 하고 바깥쪽을 어플리케이션 레이어라고 한다. 커널은 하드웨어와 직접적으로 상호작용을 하는 부분으로, OS의 핵심 파트이다. OS의 핵심 기능은 1. HW/SW resource의 관리 2. Application에 서비스 제공으로 이해될 수 있다.

Unix kernel의 경우 위와 같은 구조를 가지고 있으며, 가장 대표적인 구조의 요소 두 개가 file subsystem과 process control subsystem 이다. 이 둘을 위한 system call이 application layer에 서비스를 제공하기 위해 준비되어 있다.
System Call / Interrupt / Exception Handling Structure
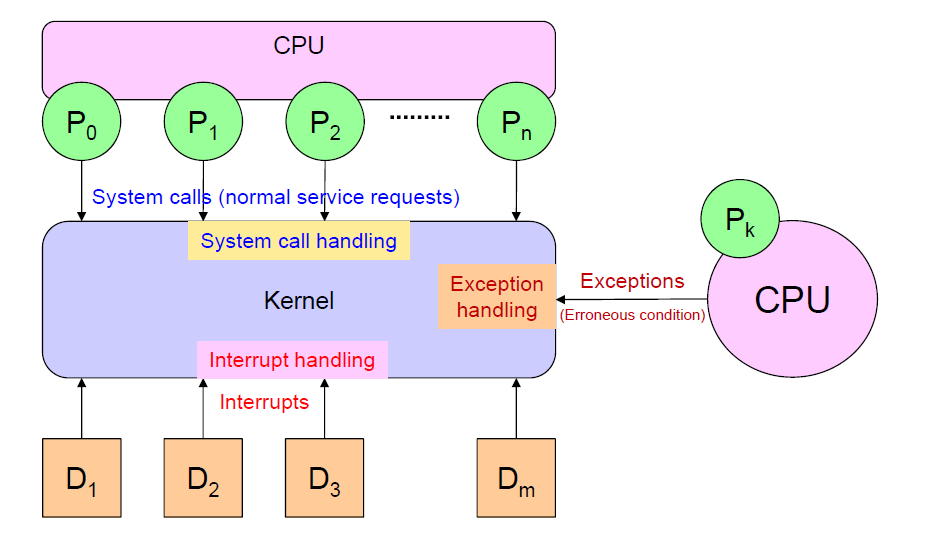
Kernel 은 여러 객체에 의해 신호를 받는다. 신호를 주는 객체는 크게 CPU, peripheral device 두 가지로 나뉘는데, CPU에서 주는 신호는 정상적인 로직을 수행하기 위한 신호인지, 문제상황에 들어오는 신호인지에 따라 system call과 exception으로 나뉜다. Peripheral device 에서 들어오는 신호는 interrupt로, 우리가 지금 사용하는 키보드와 마우스, SSD 등이 interrupt 방식으로 작동한다. 임베디드시스템에서의 인터럽트와 유사한 맥락이지만 kernel에 구현된 interrupt handling은 더욱 정교하고 복잡하다.
System Call
운영체제는 수많은 기능을 갖는 function들로 이루어져 있다. 독립적으로 돌아가는 program(process)가 아니므로 main 함수가 필요없다. 운영체제를 메모리에 올리는 것은 library를 메모리에 올리는 것이라 생각하면 된다. 커널은 memory resident 로 대기하고 있을 뿐 main() entry point 가 없다. User application을 만드려면 안에 있는 kernel function 을 활용해야 하는데, 바로 접근할 수는 없고, system call 이라는 것을 활용해야 한다.

또한, 커널에 있는 코드를 어플리케이션 코드가 바로 액세스할 수도 없고 컴파일 후 링킹하는 단계에서 둘을 링크할 수도 없다. 이러한 부분을 해결하기 위해 OS를 설계한 방식은 다음과 같다. 1. Library 함수를 만들어준다. System call 함수가 330개라면, library 함수도 330개가 만들어져 있어야 한다. User program은 library 함수와 linking 된다.
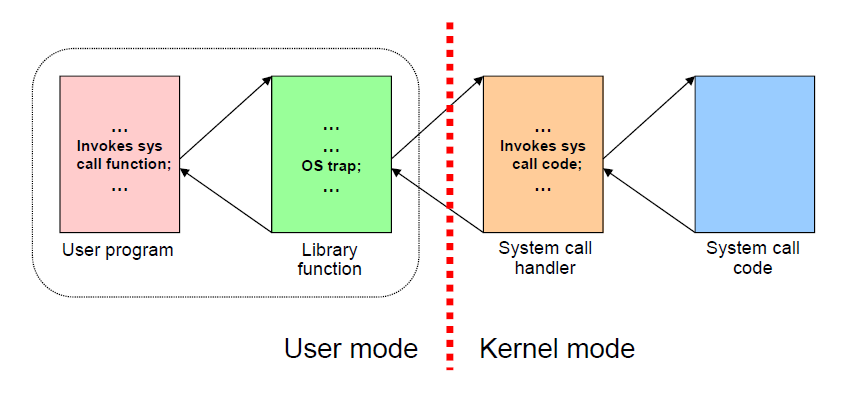
System call을 당하면 CPU는 user mode에서 kernel mode로 변경되게 된다. 이는 CPU IP들을 설계할 때 하드웨어적으로 구현된 것이다. 이 두 모드가 나뉘는 이유는 system의 안전성 때문이다. kernel 모드에서는 user mode에서 다룰 수 없는 machine instruction을 다뤄야 하며, 이를 privileged instructions 라고 한다. 안전성을 이유로 민감한 instruction 을 돌릴 수 있는 권한을 모두에게 줄 수 없다. Privileged instruction의 예로는 다음 명령어와 레지스터의 조작이 있다.
| Manipulate memory management register | LGDT, LLDT, LTR, LIDT, SGDT, SLDT, SIDT, STR |
| Load and store control registers | MOV {CR0 ~ CR4} |
| Invalidate cache and TLB | INVD, WBINVD, INVLPG |
| Performance monitoring | RDPMC, RDTSC, RDTSCP |
| Fast system call | SYSEXIT, SYSENTER |
여기서 Unix 의 system call과 Linux의 system call은 유사하지만 다른 점이 있는데, 차이는 trap과 software interrupt 의 사용에 있다.
Unix의 경우
특정 system call number 가 register에 넣어져 system call 이 호출될 시 library 함수가 실행되다가 trap을 건다. 이는 software interrupt 와 같은 개념이다. 이후 CPU가 하드웨어적으로 kernel mode로 바뀌며 trap에 의해 system call handler가 실행된다.
Linux의 경우
syscall이라고 한다. 다른 운영체제에 비해 훨씬 적은 system call 의 종류가 구현되어 있다. System call handler 는 kernel space에 있는 함수를 직접 호출할 수 없고, system call을 실행하겠다는 신호를 준다. 이 신호는 software interrupt로, x86에서는 syscall을 위한 interrupt number는 128입니다. System call number는 register (%rax) 에 들어가있게 되는데, 이것이 맞는 번호인지 확인하기 위해 다음 system call을 활용한다.
call *sys_call_table(,%rax,8)
Interrupt
Interrupt는 unexpected external event에 의해 발생된다. Interrupt 가 서비스되는 방식은 우선 machine instruction cycle 을 들여다보아야 한다.
- IF
- ID
- MEM
- EX
- ** Interrupt checks & handling **
위와 같이 interrupt check 와 handling 을 instruction cycle 내에서 synchronous 하게 진행하는 이유는, asynchronous 하게 진행하려면 save해야 할 정보가 지나치게 많아지기 때문이다. 즉, 하드웨어의 설계를 최대한 간단한게 만들기 위한 타협이라고 볼 수 있다. Kernel에서 interrupt 를 받으면 진행하는 단계는 다음과 같다. a. 현재 context 저장. b. interrupt 원인 파악. c. serve interrupt d. 이전에 실행하고 있던 context 를 restore.
Unix의 경우
Kernel 함수 안에 interrupt handler가 구현되어 있고, 현재 실행중인 process 의 context 안에서 처리된다. 이를 process context에서 처리된다고 한다.
Linux의 경우
실행중인 process와는 다르며 고유의 stack (interrupt stack)에서 실행되는 interrupt context 에 의해 interrupt가 service 된다. 'current macro'는 interrupt 가 걸렸던 process 를 가리키며 block 될 수 없고 sleep 할 수 없다. Interrupt 는 top half 와 bottom half 두 파트로 나뉜다.
File Subsystem
모든 파일에는 inode (index node) 가 하나씩 있다. inode는 파일이 위치하는 disk layout, number of links, size, owner, access permission 등을 가지고 있다. 파일에 수정을 가할때는 kernel 에서 inode 를 inode table 로 읽어들여온다. 아래 그림과 같이 process에 user file descriptor table이 있고, 그것이 모든 프로세스가 공유하는 공간인 file table로의 포인팅한다. File table은 실제 disk layout 정보를 가지고 있는 inode table의 entry로 향하게 된다.

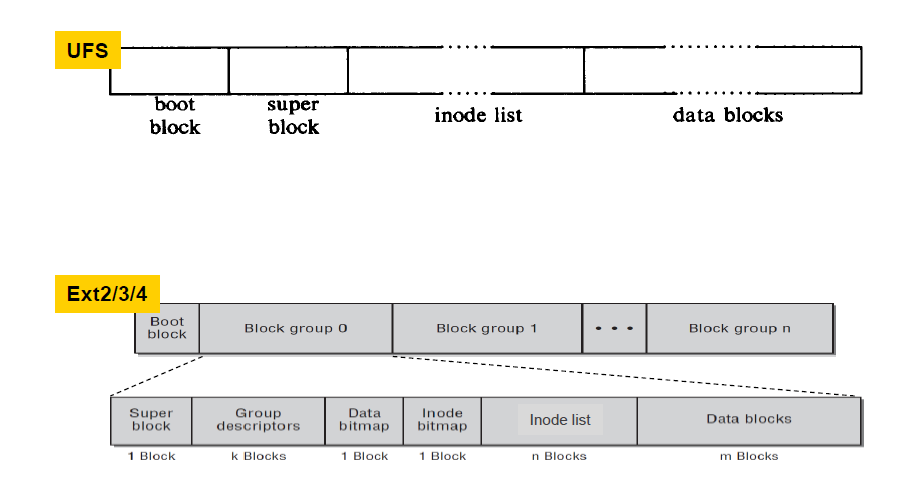
위 그림을 정리하면 Unix File System (UFS)의 경우 file system의 앞 주소에는 file system에 별로 관련이 없어보이는 bootstrap code 를 가지는 boot block 이 있고, 이후에 오는 super block은 file system 전체에 대한 metadata, inode table의 inode는 file에 대한 metadata 이다.
리눅스에서 쓰는 EXT 2/3/4 버전은 조금 다르게 구성되어 있는데, 각 block group 으로 file system이 나뉘어져 각 block group에 super block, inode list 등의 요소가 있다. 이는 한 block group 안에서 찾는 방식으로 search space를 줄이기 위함이다.
두 운영체제의 공통사항으로는 Block device 를 읽기 위해서는 buffering mechanism이 사용된다. 1. kernel 공간 안에 buffer pool을 두고 2. secondary storage device 에서 data 읽을 때는 block 단위로 읽는다. 3. 읽은 데이터는 kernel 공간 상의 buffer pool로 가져오며 4. 그 block에서 application data가 원하는 부분만 다시 읽어 가져온다.
Process Subsystem
Program = an executable file
Process = an instance of a program in execution
System call은 직접적으로 process subsystem의 역할과 연결된다. 만약 interrupt 가 한꺼번에 여러 개 들어오면 interrupt level에 둔 priority를 참고해 더 먼저 service 하여야 할 interrupt 를 결정한다.
Process subsystem에서의 shell의 역할은 application utility로서 사용자의 입력을 받고 해석하여 서비스를 사용자에게 제공하는 것이다. 1. command input 받기 2. command 실행시키기 위해 built-in으로 가지고 있는 기능이 아닌 경우 3. 새로운 child process fork, exec, wait 순으로 실행. Process control을 위한 system call로는 fork(), exec(), wait(), exit() 이 있다. Inter-process communication (IPC)에는 signal, pipe, shared memory, socket 과 같이 여러 primitive 들이 있다.
Process에 대한 이해에 앞서 그것을 실행할 수 있게끔 하는 executable file에 대한 이해가 선행되어야 한다. Header, text section data section ... 등으로 section 단위로 나누어져 관리되는데, 처음 컴파일 시 relocatable object 로 구성되어 있고 linking 단계를 지나면 executable and linkable format (ELF)가 된다. Reloacattable object 자체만으로는 실행 가능한 포맷은 아니면 실행이 가능하려면 linking이 되어야 한다.

Process가 실행되면서는 function call 이 있을 때마다 stack frame 이 push되며 return 시 pop 된다. Stack 자료구조의 활용과 같은 맥락으로 push, pop 용어가 사용되는 것을 알 수 있다. 이 stack frame에는 function parameter, function의 local variable, 이전 stack frame 의 내용을 cpu에서 복원하기 위해 필요한 정보, 예컨대 program counter (PC) 값과 stack pointer의 값이 포함되어 있다. 함수가 호출될 때 user stack과 kernel stack 동시에 stack frame이 추가된다.
Process 관리를 위한 자료구조에 대해서도 알아본다. Process의 context 가 main memory에 들고, virtual memory system을 사용한다면 region이 조각날 수도 있다. 이 조각들 각각의 단위는 page라고 한다. 이 경우 page table을 사용하여 page 단위로 나누어 memory에 할당하고 관리하는데 이것의 역할은 virtual address를 real address로 변환해주기 위한 address mapping table 이다.
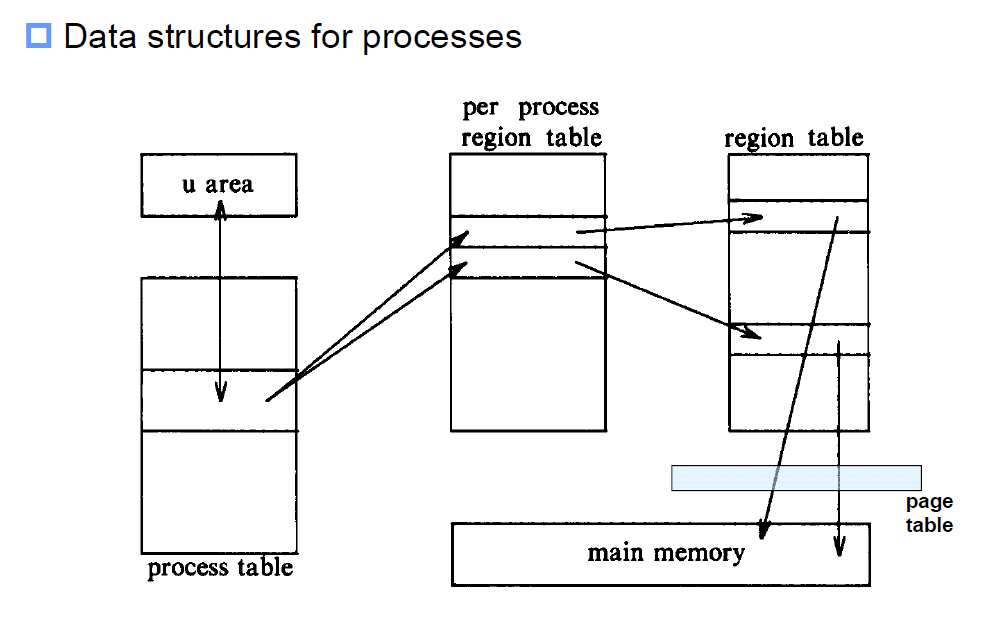
Unix의 경우
위 process 자료구조에 대한 그림은 Unix 시스템의 경우에 국한된다. Linux는 조금 다른 scheme을 가지는데, PCB라는 것을 process descriptor라는 영역으로 따로 만들어 관리한다. Unix process 자료구조의 구조와 작동 메커니즘은 다음과 같다.
a. Unix는 process에 대한 속성정보를 process table 의 slot과 u-area에 나눠 저장하고 관리한다. Process table의 entry는 u-area 에 대한 포인터, 누가 process를 가지는지, 프로세스가 block되어 sleep 상태일 때 event descriptor에 대한 정보가 있다.
b. Process 가 갖는 모든 region에 대한 정보를 저장하는 per-process region table이 있다.
c. System 안에 있는 메모리의 모든 region 정보를 관리하는 region table이 있다. 이것은 global table 이다.
d. 그 region 들이 virtual memory 상에서 page 단위로 흩어지는 경우 page table이 따로 존재한다.
e. Page table 이나 region table 통해 main memory 주소로 pointer가 나간다.
여기서 u-area가 무엇일까요? 각 프로세스마다 하나씩 있는 이것은 process의 control and status information을 가진다.
- pointer to the process table slot
- 현재 들어온 system call에 대한 parameter, return value, error code
- File descriptor
- Internal I/O parameter
- Current directory and current root
- process and file size limits
그렇다면 process table slot 과 u-area를 구분해 나눠놓은 이유는 무엇인가? 메모리 효율성 때문이다. Process table slot 에 있는 process 정보와 u-area 에 있는 process 정보를 합하면 수 kilobyte 에 달할 만큼 양이 상당히 크다. 따라서, process 마다 process 의 상태와 관계없이 항상 필요로 하는 정보는 process table slot에, process가 실행 중일때만 필요한 정보는 u-area에 저장한다. Process table 의 정보는 항상 kernel 에서 접근할 수 있도록 kernel 안에 존재하고, 어느 한 순간에 실행중인 process는 하나이므로 실행중인 process의 u-area만 kernel 공간에 둔다.
(여기서 u-area에 저장되는 정보는 정말 process가 'running' 상태일때만 필요로 하는 정보일지에 대한 고민이 필요하다.)
Linux의 경우
Linux의 경우 <linux/sched.h> 에 정의되어 있는 task_struct에 process 에 대한 속성정보인 process descriptor 가 저장되어 있다. Process descriptor에는 실행되고 있는 프로그램의 정보가 저장되는데, 예로서는 열린 file, process의 address space, pending signal 등이 있다. 이것은 kernel 의 공간을 세심히 관리하기 위해 'slab allocator'라는 것에 의해 할당된다. 비교해보면 Linux는 u-area와 process table을 따로 구분하지 않고 process descriptor를 task_struct 라는 구조체 안에 저장하는 형태로 process의 속성정보를 관리한다.

u-area에 저장된 프로세스의 상태를 포함해 프로세스와 관련된 모든정보들의 총 집합을 context 라고 한다. 여기에는 global user variable 및 data structure, machine register 값, user 및 kernel stack 정보, process table slot 과 u-area 에 저장된 정보가 있다. CPU가 어떤 process를 실행할 지 결정한 이후에는 실행될 process의 context 가 올라가야 하는데, 이를 context switch 라고 한다. 여기서는 context saving 과 restoring, 항상 두 단계의 일이 벌어진다.
주의할 점은 kernel mode 에서 user mode로 switch를 하는 것은 context switch 라고 할 수 없다는 점이다. Unix 시스템을 자세히 따져보면, 사용자 process가 자기 code를 실행하다 system call 또는 interrupt에 의해 kernel mode 로 바뀔 때는 한 process 의 context 에서 실행된다. 현재 실행중인 context 가 interrupt handler나 system call hander에게 자기 context를 빌려주기 때문에 context의 전환은 일어나지 않는다.
프로세스의 관리를 위한 시스템 콜로는 exec(), fork(), exit()가 있다. 각각에 대해 간단히 살펴본다.
- exec() : 현재 실행중인 code, data 모두 버리고 새로운 실행파일에 가서 실행코드와 데이터를 가져와 그 프로그램을 실행한다.
- fork() : 해당 system call은 parent 가 child를 새로 생성하는 system call로서 호출한 process의 각 region을 복사 후 child에 넘겨준다. 작동 메커니즘은 다음과 같다. a. old process의 address space를 duplicate . b. 새로 생성되는 child process에 할당. (필요한 경우에는 region을 복사하지 않고 share 가 가능하다.)
- exit() : process 가 종료될 때 호출하는 system call 로서, process가 현재 사용해오던 모든 region을 반납한다.
그렇다면 각 state에서의 동작과 다음 state로의 움직임이 일관적이어야 한다. 이를 위해 finite state machine 으로 나타낼 수 있도록 설계되어 있다. 이는 간단하게 나타내면 다음과 같은 모양을 가진다. Ready 상태에서 scheduling 받으면 일단 kernel running에 들린 후 user mode 로 가서 application code 를 실행하게 된다.

Unix의 경우
3번은 메모리를 할당받은 상태, 5번은 메모리를 뺏기는 상태이다. 7번 Preempted 상태는 ready 상태와 아주 비슷한 속성을 가지는데, preempted 상태에서는 kernel running을 거치지 않고 바로 user running을 진입할 수 있다.

위에서 설명한 context switch는 process가 kernel running 에서 asleep 상태로 변경될 때에만 가능하다. 이 때문에 unix kernel 이 non-preemptive kernel 로 분류된다. 이는 초기 Unix 시스템이 설계될 때 kernel data structure의 consistency를 지키기 위한 design choice 로 설명된다.

예를 들어 위 그림과 같이 bp1이라는 데이터를 process의 실행과 직접적으로 관련있는 임의의 양방향 연결리스트에 끼워넣으려면 포인터가 총 4개가 바뀌어야 한다. 그 작업을 하는 중간에 context switch가 발생해 같은 양방향 연결리스트에 접근하고, traverse 한다면 잘못된 데이터로 접근할 가능성이 매우 커지게 되고 오작동을 야기할 수 있다.
Linux의 경우
Fully preemptive 한 kernel 이다. 오른쪽 running 상태에 있다가 time quantum이 끝나 preemption을 당하면 다시 ready 상태이다. Context switch는 어느 때에도 요청될 수 있고 lock을 가지고 있지 않아 reschedule 이 가능한 안전한 지점이라면 진행까지 가능하다.

위 그림에서 가장 아래 원을 보면 task interruptable과 task uninterruptable이 있는데 sleep 상태가 두 가지 있음을 뜻한다. 전자는 process가 원하는 event가 발생하길 기다리고 있지만 그 특정 event가 발생하지 않더라도 signal이 나한테 오면 wakeup 하는 것이고, 후자는 특정된 event 만 기다리고, signal 에는 wakeup 하지 않는다.
첫 글부터 굉장히 길어졌는데, 지금까지 file subsystem 과 process subsystem 전반에 대해 다루었다. 다음부터는 file subsystem의 한 요소인 buffer cache 의 상세한 부분과 scenario study까지 다루도록 한다.
'CS > Operating Systems' 카테고리의 다른 글
| [Principles][4]File System(algorithms for allocation and freeing of file system resources) (0) | 2023.04.12 |
|---|---|
| [Principles][3]File System(locating files and data blocks) (0) | 2023.04.12 |
| [Principles][2]File System(algorithms for in-core inode) (0) | 2023.04.11 |
| [Principles][1]Buffer Cache (0) | 2023.03.26 |