Image courtesy of Prof. Young Ik Eom - SKKU,
Maurice J. Bach - The design of the UNIX operating system

저번 글에서는 파일시스템에서 inode를 메모리 또는 in-core로 받아내고 내보내는 알고리즘들을 살펴보았습니다. 그것이 아래 사진에서 보이는 iget()과 iput() 입니다. 이번에는 inode를 참조하여 파일 시스템 안에서 필요한 data block을 찾아내는 방법인 bmap() 알고리즘에 대해 알아본 후, directory 는 어떻게 관리되며 pathname이 주어지면 파일을 어떻게 찾아내는지 서술된 namei() 알고리즘에 대해 알아보겠습니다.
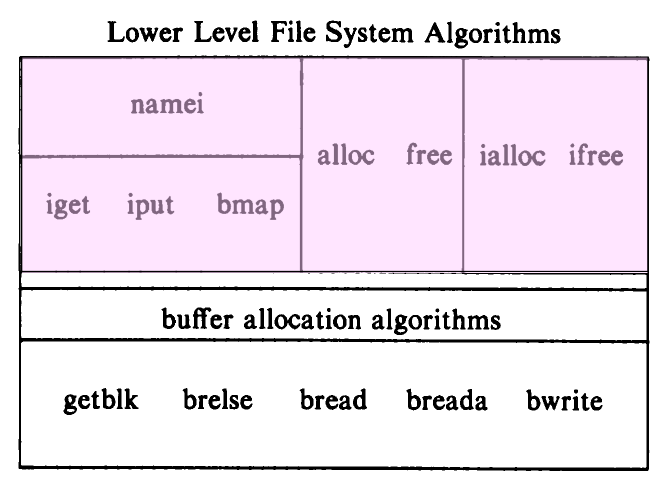
위 그림에서 계층상으로만 보면 namei()가 bmap()보다 상위에 있는 것을 볼 수 있습니다. namei()가 bmap()을 호출한다는 뜻이 됩니다. bmap()뿐 아니라 iput(), iget()도 포함됩니다.
File Storage
우선, 파일시스템에서 커널이 데이터를 어떻게 저장하는지를 알아보겠습니다. 파일시스템 안에서 한 파일의 데이터는 연속적으로 저장되는것이 아닌 흩어져서 저장되어야 합니다.

파일의 데이터를 연속적으로 저장해야 하는 policy를 적용한다면 아래 File A, File B, File C 가 나란히 있는데 File B의 크기가 더 커지는 상황을 마주하여 C를 옮기거나 B를 옮겨야 하는 이슈가 발생합니다. 나란히 저장해야 한다는 policy에 의해 C를 옮기고 B를 증대시키는 방식은 memory bandwidth를 높일 뿐 아니라 중간에 빈 공간이 만들어지는 fragmentation 문제가 발생합니다.
방금까지 ordinary file system에 대해서는 discontinuous allication 기법을 사용한다고 했지만, 메모리에 저장된 process image를 뜻하는 swap 영역은 예외입니다. Swap file system은 storage로 memory의 process image 밀어내고 가지고 오늘 과정이 매우 빨라야 해 그때는 continuous allocation 기법을 사용합니다.
bmap() : locating physical blocks for data within a regular file
이렇게 데이터를 저장하는 파일시스템에서 파일의 상태 및 여러 metadata를 가지는 inode는 13개의 entry가 있습니다. 그 중 10개는 direct data block pointer, 나머지는 indirection에 대한 포인터입니다. Indirection이란, 포인터를 따라가면 실제 data block이 있지는 않고 다시 데이터 주소의 묶음을 가지고 있는 테이블을 이용해 가리킬 수 있는 data block의 양을 증대시키는 기법을 뜻합니다. Unix system에서는 indirection을 세 차례씩 걸쳐서 할 수 있습니다. 이렇게 direct block pointing과 indirection을 여러 차례 하여 가리킬 수 있는 데이터를 최대화 시키는 전략을 hybrid multi-level indexing 이라 합니다.
Unix File System에서는 direct block 10개, single indirect 1, double indirect 1, triple indirect 1개가 있습니다. Unix 에서는 inode 하나의 크기가 64 byte 였고, 여러 inode에 들어가는 12 byte를 제외한 52 byte에 13개의 file data의 위치와 관련된 정보가 들어갔습니다.
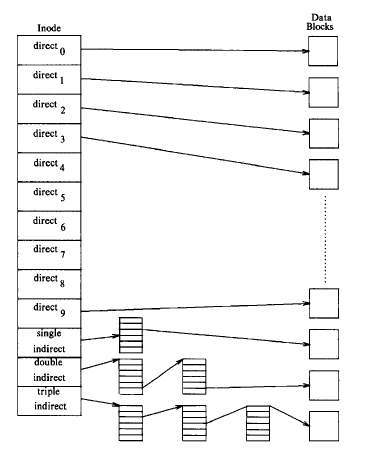
Triple indirect가 point할 수 있는 숫자만 보면 256 X 256 X 256 = 2^24 = 16GB 입니다. 따라서 위와 같은 방식으로 16GB가 조금 넘는 파일의 크기를 Unix에서는 지원하도록 하였었습니다.
그렇다면 이렇게 큰 파일을 위해 필요한 데이터를 Unix에서는 어떻게 찾아냈을까요? 이것을 해주는 것이 bmap() 알고리즘입니다. 파일 안에서의 데이터는 byte offset 으로 접근해야 하는데 실제로 필요한 것은 physical block number가 될 것입니다.

'/d/x는 Root 밑 d directory 밑 file x를 뜻하는데, file x의 block 크기를 통해 우리는 offset이 무슨 logical block에 해당하는지 알 수 있습니다. 예를 들어 1개의 block size가 1KB = 1024B라면, offset=1000 인 경우, 0번 logical block임을 알 수 있습니다. 여기서부터는 inode를 참고하여 physical block number까지 알아냅니다. 아래에 pseudocode 로 설명되어 있습니다.

예시를 보겠습니다. Data block size 하나가 1024B 일때를 가정합니다.

Hybrid multilevel indexing 방식으로 inode와 파일 탐색 policy를 설계하면 아주 큰 파일의 뒤쪽 데이터를 요청할 때 triple indirect 까지 가야합니다. 이는 3번까지 접근과정이 추가된다는 뜻으로, 이렇게 block을 읽어들일 때마다 해당 block이 buffer cache 안에 들어와있지 않을 때 process는 sleep 할 수 있습니다. 이 방식으로는 overhead가 발생해 느려지고 system performance에 악영향을 미칩니다.
이를 해결할 수 있는 방법이 block size를 늘리는 방법이나, 이렇게 하면 fragmentation 문제가 발생할 수 있고, 또 하나의 대안은 inode에 데이터 또한 저장하는 것입니다. File size가 아주 작다면 file data 를 해당 block 안에 다 넣을 수 있을 것이고, file size가 한 block의 크기를 초과하면 그 file의 마지막 fragment를 inode 안에 저장합니다.
namei() : pathname to inode
우선, 파일 시스템에서 디렉토리 파일과 pathname 에 관해 알아보겠습니다. 파일시스템에서 파일들은 hierarchical structure를 가지게 되고 이것은 directory라는 개념이 존재하기 때문에 가능합니다. 윈도우에서 '폴더'라고 불리는 것이 그것이죠. Directory는 inode number와 file name entry를 가지는 table로 구성되어 있습니다. Empty directory entry 는 inode number가 0으로 표시되어 있습니다.

Regular file 처럼 directory도 Read/Write/Execute (rwx) permission 이 있습니다. Write의 경우, 처음 보면 directory에 데이터를 쓰는게 어떻게 가능한가 의아할 수 있는데, directory에 대한 write permission이 있어야 그 process는 해당 directory 밑에 새로운 파일을 생성할 수 있고 기존에 있던 파일도 삭제가 가능합니다. 같은 현상이지만 다르게 설명하면, 위에 보이는 table entry가 수정 가능한가에 대한 이야기이죠.
전체 파일 시스템 안에서의 search는 여러 어플리케이션을 만들 때 필요합니다. Pathname이 주어지면 파일을 접근하는 알고리즘이 namei() 입니다. 아까 bmap은 파일이 주어졌을 때 그 안에서 필요한 데이터가 담긴 physical disk를 가져오는 역할을 했다면, 이 알고리즘은 더 큰 범위에서 필요한 pathname이 있다면 그것에 해당하는 파일을 가져오는 역할을 합니다. 이것이 가능하려면 우선은 pathname을 해당 파일의 inode로 변환할 것입니다.
Pseudocode로 살펴보겠습니다.

파란색으로 칠해진 알고리즘의 나열이 왜 쓰이는지를 한 번 생각해보겠습니다.
- bmap() : 블록에서 원하는 데이터가 어디에 있는지 byte offset을 받으면 physical block을 가져옵니다. bmap()을 하여 실제 inode의 physical block을 가져온 후 block 안에서
- bread() :
- brelse() :
그림으로 된 예시를 보겠습니다. 우선 아래와 같이 검색을 하는 과정은 execute 권한이 필요합니다. 이후 file pathname을 kernel이 system call 단계에서 받아 내부적으로 그 file의 read-write를 진행해주기 위해 kernel data structure를 setting 하는 과정에서 path name을 inode로 바꿔줍니다.
a라는 파일로부터 시작합니다. a가 처음에 directory인지 regular file인지 커널에서는 아직 알지 못합니다. inode를 읽는데, 13개의 pointer를 참조하며 directory block을 하나씩 읽어보며 우리가 원하는 x라는 파일이 있는지 block을 하나씩 들어내서 찾아봅니다. x라는 파일이 나왔다면 그것의 inode 번호를 directory에서 찾아봅니다. inode 번호를 가지고 iget()을 실행합니다. 그렇게 하면 해당 inode가 in-core(memory)로 읽혀 들어오는데 그 안에서 13개의 pointer (hybrid multilevel indexing 기법)으로 필요한 data block을 모두 얻어낼 수 있습니다.

마지막으로, namei() 알고리즘에 대해 글로 된 예시를 보겠습니다.

'CS > Operating Systems' 카테고리의 다른 글
| [Principles][4]File System(algorithms for allocation and freeing of file system resources) (0) | 2023.04.12 |
|---|---|
| [Principles][2]File System(algorithms for in-core inode) (0) | 2023.04.11 |
| [Principles][1]Buffer Cache (0) | 2023.03.26 |
| [Principles][0]General Summary (0) | 2023.03.21 |