Image courtesy of Prof. Young Ik Eom - SKKU,
Maurice J. Bach - The design of the UNIX operating system

이전 글에서는 필요한 데이터를 어떻게 찾아가는지 서술한 알고리즘인 bmap()과 namei()에 대해 알아보았습니다. 중요한 점은 내부적으로 kernel은 inode를 사용해 파일시스템 자원의 위치를 파악한다는 것이었습니다. 이번에는 file system의 리소스를 할당하고 해제하는 alloc, free, ialloc, ifree에 대해 알아보겠습니다.

우선, Unix file system의 superblock에 대해 알아볼 필요가 있습니다. 첫 글에서 Unix의 파일 시스템은 다음과 같이 bootblock, superblock, inode list, datablocks 구간으로 나뉘어있다고 하였습니다. Superblock의 정보는 file system 전체에 대한 metadata 로서, 이것에 문제가 생기면 전체를 사용하지 못할 수 있습니다.
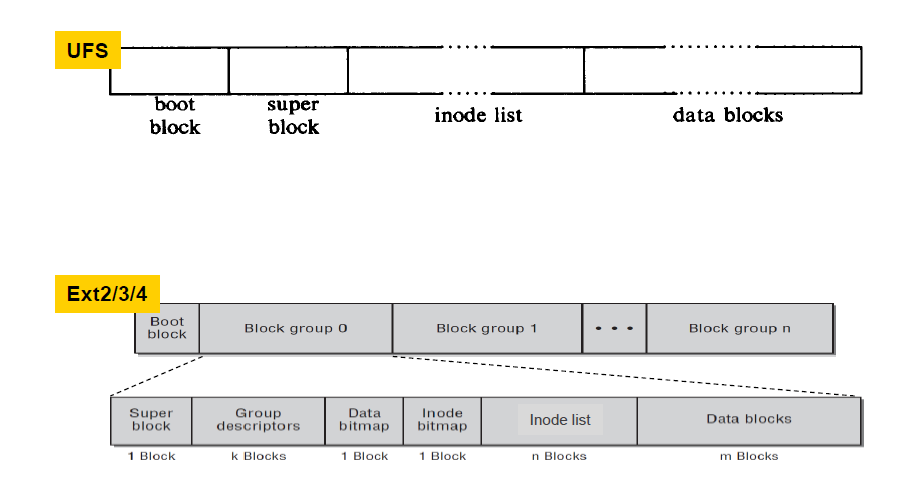
Superblock은 매우 자주 접근되는 자료구조로, file system unmount 될 때까지(전체가 사용되지 않을 때까지) memory에 들어와 있습니다. 또한, consistency를 강하게 유지해야 하는 component로서, write to disk가 수시로 일어나야 하는 부분입니다. File의 metadata가 변경되었는데 disk write 되지 않은 상태에서 volatile memory 가 날라가면 시스템에 심각한 손상을 줄 수 있겠죠? Superblock은 다음 field를 가집니다.
| 전체적인 정보 | File system의 크기 ..etc.. |
| Data Block | File system에서 사용 가능한 free block numbers File system에서 사용 가능한 free block의 리스트 Free block list에서 다음 free block의 index |
| Inode | Inode list의 사이즈 File system에서 사용 가능한 free inode numbers File system에서 사용 가능한 free inode의 리스트 Free inode list에서 다음 free inode의 index |
| Data block & Inode 공통 | Free block과 free inode list를 위한 lock fields Superblock이 변경되었음을 표시하는 flag |
inode Allocation / Freeing
이제부터는 inode 할당과 할당해제에 대해 알아볼건데 그 전에 inode의 특성에 대해 간략히 다루고 가겠습니다.
- File system은 inode 순서대로 inode list를 보관하고 있음
- Inode에는 type field 라는 것이 있는데 이것이 0이 되면 inode가 free라는 뜻
- Process에 새 inode가 필요할 때는 disk에서 매번 할당받을 수 있지만 그렇게 하면 disk access bandwidth만 차지할 뿐 효율적이지 않음. 따라서, free inode 일부를 superblock에 caching 하여 활용함.
Superblock 또한 disk에 위치하는데 어떻게 caching이라는 것이 성립하는가 하실 수 있는데, 바로 위에서 superblock은 unmount 될 때까지 memory에 올라와 있다고 하였습니다. 또한 여기서 말하는 caching은 inode 전체를 superblock에 갖다놓는 것이 아닌 free 인지만 확인하고 다른 field는 제외한 free inode number 만을 가지고 오는 것입니다.
ialloc(), ifree() 알고리즘에서 다루는 부분이 바로 파일을 생성시켜 kernel process에서 inode에 대한 요청을 받는다면 memory 안의 superblock에 들어와있는 free inode 중 하나를 할당해주는 것입니다. 만약 superblock에 있는 free inode list의 모든 inode를 할당해버렸다면 다시 disk로 돌아가 free inode를 하나씩 검사해가며 한꺼번에 superblock free inode list에 위치시킵니다. Pseudocode로 보겠습니다.

if(inode list in superblock is empty) 부분에서 'remembered inode' 라는 새로운 개념이 보이는데 이것은 아래에 그림을 이요한 추가설명을 하겠습니다. 또한, 빨간색으로 표시되는 부분은 contention issue에 대한 handling code 인데 이 또한 뒤에서 설명하겠습니다.
위 pseudocode 에서는 여기서 이전에 배웠던 iget() 과 iput() 함수가 보입니다. Superblock free inode list에서 inode number를 얻어낸 다음 iget()을 하여 실제 inode block을 buffer cache에 갖다놓습니다. 마지막으로 새로 inode를 할당했으면, 새로 생성되는 file의 정보, 예를 들면 file type 과 permission 등 모두 consistency를 위해 disk에 갖다씁니다.
아래 그림을 통해 알고리즘이 어떻게 작동되는지 보겠습니다. 위에서 언급한 remembered inode란 superblock에 위치한 free inode list 중 마지막으로 list에 올라가있는 free inode number를 이야기합니다. 이 inode number를 기억하였다가, 모두 다 사용하고 나면, disk에서 새로 불러들일 때 그 다음 수부터 가져오게 됩니다. 아래의 예시로는 470번까지 사용하였으니 그 숫자보다 큰 inode number를 가진 inode를 불러오는 것이죠. 아래의 그림에서는 그것이 471번이네요. 이후에 다시 ialloc()을 하면 471번 inode가 해당 프로세스에 할당되고 index는 475번을 가리키게 됩니다.

그렇다면 file system superblock에서 할당한 inode list의 최대 크기를 넘어서서 불러오려고 하면 어떻게 할까요? 불러오는 방식은 circular scan 이기 때문에 처음부터 불러오게 됩니다.
이제 inode를 할당해제하는 ifree() 알고리즘을 살펴보겠습니다. 통상적으로 어떤 file 이 삭제될 때 이 알고리즘이 사용됩니다. 삭제되면 file의 inode가 반납되어야 합니다. 이 알고리즘이 호출되었다는 것은 iput() 알고리즘에서 다음을 이미 수행하였다는 것이 선행되었음을 의미합니다.
- File type field를 0으로 세팅 되어있음
- Inode를 disk에 write 되어있음
아까 remembered inode에 대해 설명하였는데, free 시 disk bandwidth를 줄이는 방법으로 remembered inode와 비교해 더 작으면 superblock에 바로 free 하는 기법을 사용합니다. 그러나 만약 superblock에 lock이 걸려있다면 어차피 나중에 찾아지게 되므로 굳이 sleep까지 해가며 기다릴 필요는 없으므로 return 합니다.

위에서 설명한 것처럼 이 ifree() 알고리즘은 iput() 알고리즘에서 호출됩니다. iput()은 memory에 올라와있는 inode를 내리는 알고리즘입니다. iput()이 호출되는 모든 상황에서 ifree() 를 호출하는 것은 아닙니다. 아래 pseudocode에서 볼 수 있듯 reference count 가 0이 되는 것은 파일이 삭제됨을 뜻하고 그렇기 때문에 file type를 0으로 만들어 준 후 ifree()를 호출하는 것입니다.

지금까지 설명한 ialloc() 알고리즘은 remembered inode를 이용하고 caching을 하고, 그로 인해 disk bandwidth가 줄고 기타등등... 여러 부분에서 매우 이상적인 알고리즘이지만, 여기서도 contention (race condition) issue 가 발생합니다. ialloc()의 pseudocode의 빨간 부분에서 그것을 handling 합니다. Contention issue가 발생할 수 있는 상황을 아래 그림의 예시로 보겠습니다. inode 'I' 를 allocation 하려고 할 때 발생하는 문제입니다.
Process A는 assign 까지 하고 sleep 되는데, assign 된 상태는 요청만 했지, 아직 불러들여와서 type field가 쓰여지지 않은 상태이므로 file system 상으로는 아직 free인 상태입니다.
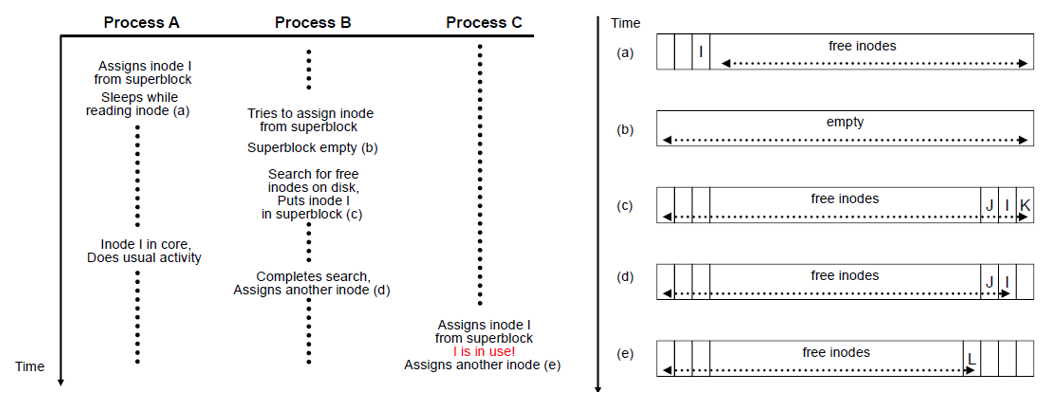
여기에서 Process B가 inode를 할당받으려고 하는데 superblock의 free inode list가 마침 비어있습니다. Disk에 가서 remembered inode number 이후부터 일일이 inode가 free임을 확인하며 한꺼번에 superblock으로 데리고 오는데요. 이 때 inode I 도 대외적(?) 으로는 free 이므로 우연히 inode 번호의 범위가 맞아떨어져 같이 데려와지는 상황이 발생합니다.
이후 Process A 가 scheduling을 받아 정상적으로 inode를 사용하게 되고 Process B는 다행이도 Process B는 Process A와 맺어진 inode A를 바로 할당받지는 않고, free inode list의 가장 오른쪽에 있는 다른 inode를 할당받아 in-core(memory)로 올라가 작동을 하게 됩니다. 그러나 Process B에 의해 superblock에 올려진 inode를 Process C가 사용하려고 보니 사용중인 상황입니다.
위 contention issue 는 다음과 같은 이유 때문에 발생합니다.
- disk에서 circular scan을 하기 때문
- superblock 을 공유하며, 그 안에 있는 free inode list 도 공유해야 하는 환경이기 때문
위 두 가지는 어쩔 수 없습니다. Superblock 과 free inode list가 아무리 크더라도 여러 kernel process가 inode 를 대용량으로 할당할 수 있기 때문에 contention 에서 완전히 자유로울 수는 없어보입니다. 그렇다고 하나의 process 가 할당할 수 있는 inode 의 양을 제한시켜버리면 application performance에 악영향을 줄 것이고요. 따라서 ialloc() 알고리즘에서 handling을 고안하기를, 해당 inode를 disk에 write 하고 release 합니다.
Disk Block Allocation / Freeing
Superblock은 free inode list 뿐 아니라 free disk block도 관리합니다. 이는 disk block number로 이루어진 grouped linked list로 관리하는데요. grouped 라고 함은, superblock free disk list 한 줄에 총 n 개의 block이 있다고 하면 실제로 free인 disk 는 n-1개이고 마지막 block은 n개의 free block에 대한 number를 가지고 있습니다.
inode와 비교해보자면 inode는 remembered inode를 이용해 disk scan을 주기적으로 하는 반면, 여기서는 모든 block 들이 연결되어 있습니다. 이는 합당한 이유가 있습니다.
- Inode 는 자료구조로, 안에 비었는지 확인할 수 있는 field 가 있지만, data block은 어느 block이 비었는지 알 수 없습니다. 따라서 미리 전부 다 찾아 grouped linked list 에 보관하는 것입니다.
- Data block은 아주 긴 list를 가질 만큼 큰 용량을 지원 (예를들어 1KB) 하지만, inode는 총 용량이 커봐야 62B입니다.
- 유저는 파일의 생성과 삭제와 밀접한 관련을 갖는 inode field의 수정보다 disk block의 수정이 더 자주 일어납니다.

allo() 알고리즘을 살펴보겠습니다. Computer system에서 관리하는 file system은 여러개일 수 있습니다. 그 file system은 전부 unique 하게 번호가 붙어있는데 file system number를 주면 해당하는 file system 에서 빈 데이터를 할당하는 알고리즘이 alloc() 입니다. 전체적인 흐름은 새로운 block을 할당해 해당 block을 buffer cache에 영역 만들어놓고 그 buffer에 대한 pointer를 return하는 것입니다. Free data block을 찾았다면 buffer에 대한 pointer return 전 그 block 안의 binary는 비어있을까요? 아마 뒤죽박죽 되어 있을 가능성이 큽니다. 따라서 Just-in-time 방식으로 내부 데이터를 null 로 모두 채운 후 buffer에 대한 pointer를 리턴해야 합니다. 아래에 알고리즘에 대한 pseudocode가 있습니다.

알고리즘에 대한 예시를 보겠습니다.

ifree() 알고리즘에 대한 pseudocode는 직접 작성해보도록 하겠습니다. 서적에 free() 알고리즘은 나와있지 않아 제 주관대로 작성해본것인데 의견 있으면 편하게 남겨주시길 부탁드립니다. 설명을 남기자면 free block list는 모든 free block의 number를 담고 있어야 해서 superblock에 대한 lock 이 풀릴 때까지 기다립니다. 또한 remembered 방식이 아니므로 이전 리스트에서 다음 block number를 point 하게끔 하는 방식으로 연결시켜 준 다음, 추가시켜줍니다.
algorithm free
Input: file system number
Output: none
{
while (superblock locked)
sleep(event superblock not locked)
if(superblock free block list full)
{
point last block number of next free block list
to the first number of previous list;
}
add a block number into superblock free list;
increment total count of free blocks;
return;
}
'CS > Operating Systems' 카테고리의 다른 글
| [Principles][3]File System(locating files and data blocks) (0) | 2023.04.12 |
|---|---|
| [Principles][2]File System(algorithms for in-core inode) (0) | 2023.04.11 |
| [Principles][1]Buffer Cache (0) | 2023.03.26 |
| [Principles][0]General Summary (0) | 2023.03.21 |