Image courtesy of Prof. Young Ik Eom - SKKU

이번에는 file subsystem에 관해 더 자세히 알아봅니다.
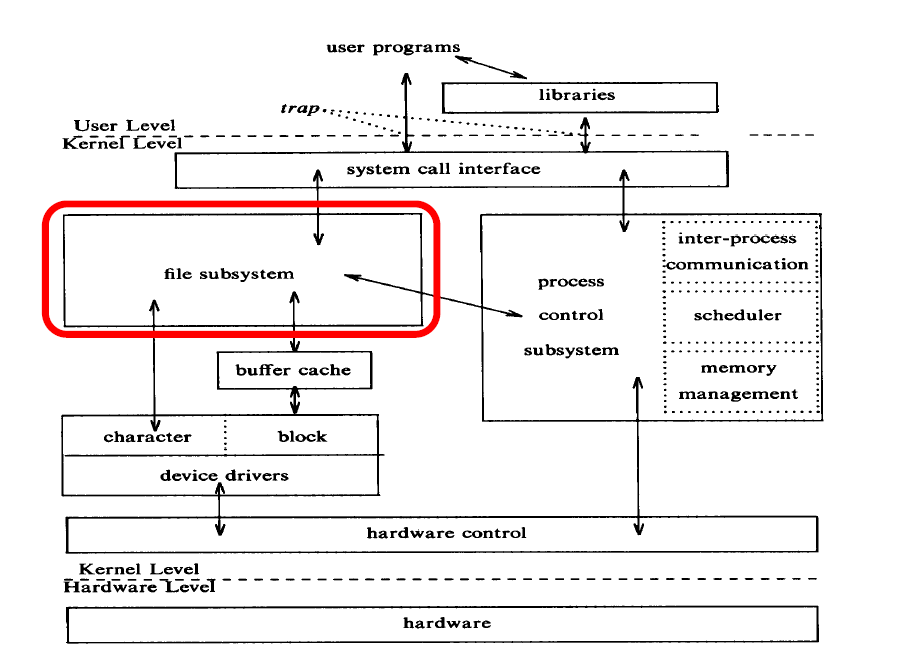
File subsystem을 구성하는 알고리즘은 다음과 같은 계층으로 나뉘어 있습니다. 아래 분홍색으로 칠해져있는 알고리즘이 어떻게 작동하는지 알아보면서 파일시스템을 이해하도록 하겠습니다. 이전에 설명하였듯, Unix file system 은 inode 라는자료구조 위주로 돌아갑니다. 이전 글에서 disk의 정보를 buffer cache에 담아서 왔던 것처럼 inode 도 disk에 상주하다가 필요할 때 inode cache 로 불러들여져 옵니다.
계층에서도 나와있지만 inode 는 자료구조이기 때문에 실질적으로 데이터 자체를 다루는 buffer에 담겨서 kernel로 들어올 수 밖에 없습니다. 이게 헷갈릴 수 있는 부분인데, 그렇기 때문에 파일시스템 관련 알고리즘은 buffer 를 통해서 작동하게 됩니다.

iget, iput, bmap, namei는 inode와 연관이 있는 알고리즘이고, alloc, free, ialloc, ifree는 super block 과 관련되어 있는 알고리즘입니다. 이름에서 힌트를 얻자면 이름 앞뒤에 붙은 'i'는 inode를 뜻합니다.
이전에 간략히 다루었듯이 Unix file system 은 다음과 같이 설계되어 있습니다. Disk는 partition으로 나뉘고, 하나의 partition 마다 하나의 file subsystem이 배정되어 있습니다. 여기에 boot block, superblock, ilist, datablock으로 나뉘게 됩니다. ilist는 inode의 모음이고, data block은 inode에서 가리키는 실제 데이터를 저장하고 있습니다.
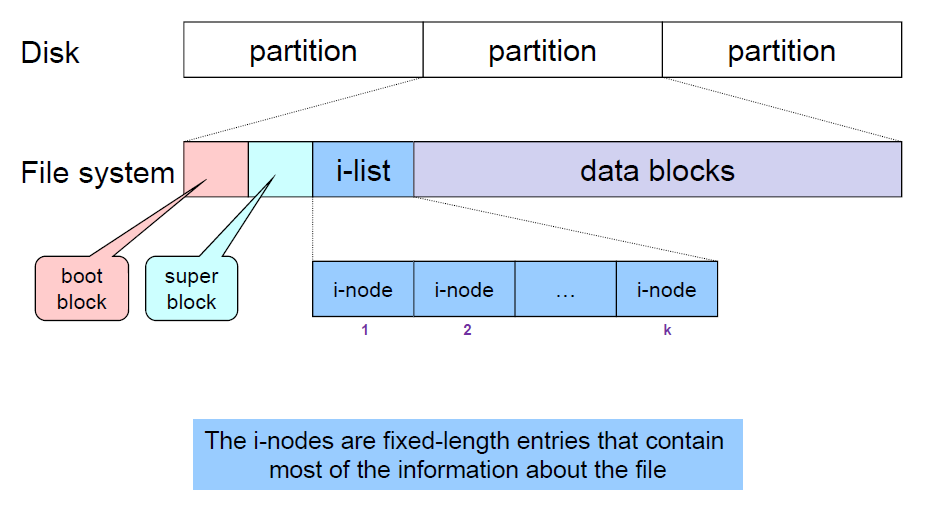
그렇다면 inode 자체 또한 disk 에 static 하게 저장되어 있는 것임을 유추할 수 있습니다. Inode 번호는 1번부터 시작하며 고정크기입니다. File subsystem이 진화함에 따라 단일 inode에 저장되는 데이터의 크기도 함께 커졌는데요, UFS의 경우 64 byte, EXT2의 경우 128 byte, 그리고 EXT4의 경우 256 byte가 되겠습니다.
예를 들어보겠습니다. Pathname /a/x 가 주어졌다면, 이는 root directory 아래 a 라는 directory 에 x 파일이 존재한다는 뜻입니다. 그렇다면 inode x가 x라는 파일의 data block을 가리킬 것인데요, 상황상 파일 x 는 3개의 block을 사용하고 있습니다. 또한 이 3개의 block은 논리적으로는 인접하지만 물리적으로는 흩어져있습니다. 지금까지 주어진 상황에서 x 의 data block을 모두 찾아가려면, inode만 가지고 온다면 파일 x의 data block 위치정보를 모두 알 수 있습니다. 다음 순서대로 따라가 보겠습니다.
- Root directory 에서는 directory a 를 찾아낸 후,
- Directory a의 inode 는 directory block 을 가리킬 것인데 이것은 inode number와 file name entry 쌍의 리스트로 이루어져 있음.
- 여기에서 file x의 file name을 찾고, 그것에 대응하는 inode number를 찾아냄.
- File x에 해당하는 inode number를 찾아 따라가면 x의 data block을 모두 찾아냄.

inode에 대해 더 자세히 알아보면, inode가 가지는 정보는 다음과 같습니다. 파일을 수정하는 행위는 last accessed time을 수정시키기 때문에 당연히 inode에도 변화를 가져옵니다. inode만 수정되고 파일 자체는 수정되지 않는 경우도 있을 수 있는데, 파일의 소유 권한을 바꿀 때가 전형적인 예입니다.
- File owner
- File type
- File access permissions
- File access times (file last modified, file last accessed, inode last modified)
- Number of links to the file
- Table of contents for the disk addresses of the file data
- File size
여기서 중요한 점은 pathname을 주면 inode까지 찾아갈 수 있지만 inode 안에서 다시 pathname을 저장하고 있지 않다는 점입니다.
위에서 설명하였듯, 파일을 읽었을 때 inode도 메모리로 불러들어와져야 합니다. File을 읽고 수정하는 작업을 하니 당연히 그것에 대한 metadata가 함께 수정되어야 하며, 이것을 하기 위해서는 메모리에서 수정 후 disk에 write 하는 방식을 취합니다. Memory로 불러들여진 inode 를 in-core inode 라고 하는데, 이 또한 hash queue와 free list로 설계되어 있습니다. 각 hash queue와 free list는 doubly linked circular list로 만들어집니다.
아래 그림을 참고합니다. Table로 이름지어진 것은 모두 메모리에 있는 것들입니다. 그림에는 없지만 user file descriptor table의 첫 두 칸은 stdin, stdout 이 될 것입니다. User file descriptor table 은 process 마다 하나씩 가지고 있는 테이블이며, file table 로 point 하는데, file table은 global 한 structure 입니다. File table에서 point 하는것이 in-core inode table 로, inode cache 라고도 합니다. 이 구조는 hash queue 와 free list로 구현되어 있습니다. 이런 점에서 저번 글에서 다루었던 buffer cache와 비슷하네요.
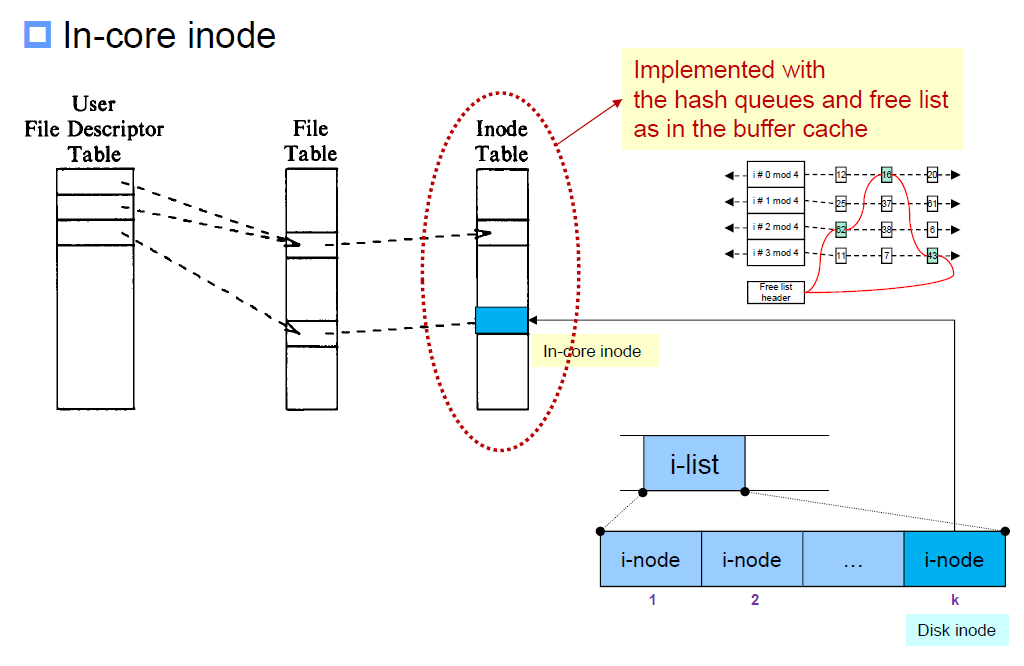
in-core inode 또는 inode cache에 있는 inode 의 정보는 disk에 담겨있는 inode 정보에 추가해서 정보를 담고 있어야 합니다. 아래에서 inode가 activate 되었다는 것은 'in-core로 들어왔다' 또는 'memory로 올라왔다' 와 같은 뜻입니다.
| 정적으로 저장된 정보들 | inode가 activate 되었을 때만 필요한 정보들 |
| 위에서 언급한 disk inode의 정보들 File owner File type ... etc |
In-core inode의 상태 Locked / Unlocked Processes that are waiting for the inode to be unlocked 참고로 지속적으로 수정이 되는 버전이기 때문에 disk의 inode와는 다른 내용을 포함할 수 있음. |
| File system에서 파일을 가지고 있는 logical device number | |
| inode number (disk inode 에서는 inode number를 저장하지 않습니다) |
|
| Hash queue pointers and free list pointers | |
| reference count |
위에 밑줄 친 reference count는 inode cache 가 inode 를 관리할 때 사용하는 기법의 특징입니다. inode cache의 구조가 buffer cache의 구조와 비슷해 헷갈릴 수 있지만 작동 방식이 다르며, 근본적인 차이는 이 reference count에 있습니다. Reference count는 해당 file의 active instance 개수를 뜻합니다. 하나의 파일에 대해 여러 프로세스가 접근할 수 있을텐데, open 될 때마다 reference count는 올라가겠죠. free list에 들어가는 inode는 reference count가 0이어야만 합니다.
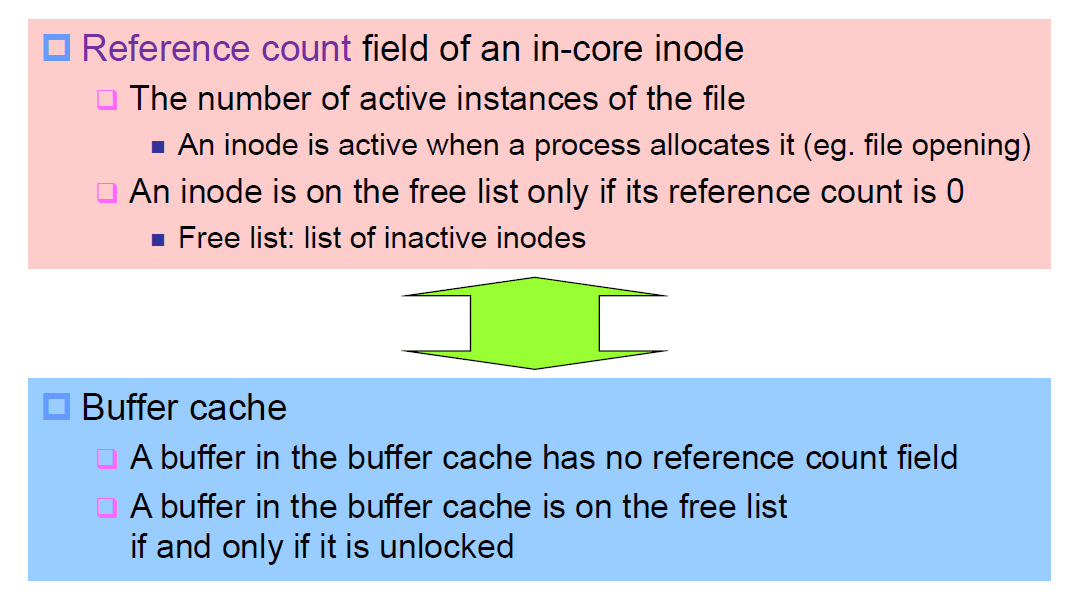
Buffer Cache : The terms "locked" and "busy" are used interchangably, as will "free" and "unlocked".
inode Cache :
왜 inode list (inode cache) 에는 reference count 라는 것을 만들어두고 buffer cache에는 없을까요? Buffer cache 에서 살펴본 내용을 복습해보면 free list 에 있을 때는 buffer cache 가 busy 하지 않을 때입니다.
iget() algorithm
그렇다면 메모리로 inode를 불러와 in-core inode를 만드는 메커니즘이 무엇일지에 대해 자연스러운 의문이 생길텐데, 이것은 iget()이라는 알고리즘으로 처리합니다. 전반적인 프로세스는 다음과 같습니다.
- Hash queue를 탐색합니다.
- Free list에서 inode를 배정받고
- Disk inode에서 read를 호출합니다. 이 점에서 getblk() 함수와 로직이 비슷합니다.
알고리즘은 다음과 같은 pseudocode 로 표현될 수 있습니다. inode 라는 리소스를 활용하는 것도 buffer cache 에서와 마찬가지로 contention issue(race condition)가 발생할 수 있습니다. 따라서, inode 가 locked 된 상태이면 sleep 하고 while loop 처음으로 돌아가도록 합니다.

Free list and error
여기서 특이한 부분은 위 pseudocode에서 파란색으로 칠해진 부분입니다. Free list가 비어있다면 error를 리턴하는 부분인데요. 이전에 buffer cache를 다루었을 때는 sleep()을 호출하여 free list에 free buffer가 걸릴 때까지 프로세스가 기다려주었습니다. 그러나 inode의 경우는 에러를 리턴하는데 이 이유는 inode라는 리소스는 보통 file open() close()에 열고 닫히게 됩니다. 이는 kernel code가 빨리 실행되면 되는 system dependent resource가 아닌 application dependent 또는 user dependent resource로 분류됩니다. 따라서 언제 리소스가 반환될지 모르는 것이고 언제까지나 process가 기다려줄 수 없다는 것이죠.
Reading from disk
다음으로 다룰 부분은 disk에서 읽어들이는 부분인데요, disk와 memory 사이에는 block 단위의 전송이 이루어지므로 block 안에서 process가 원하는 inode를 찾아야 합니다.
read inode from disk (algorithm bread() -getblk());읽어들인 후 원하는 inode를 찾는 방법은 간단한 수식을 이용하는 것입니다.
Block# = ((inode# - 1) / # of inodes per block) + start # of the inode list
Byte offset = (inode - 1) mod (# of inodes per block)) * size of disk inode
위 식을 활용할 수 있는 간단한 예시를 들어보겠습니다.
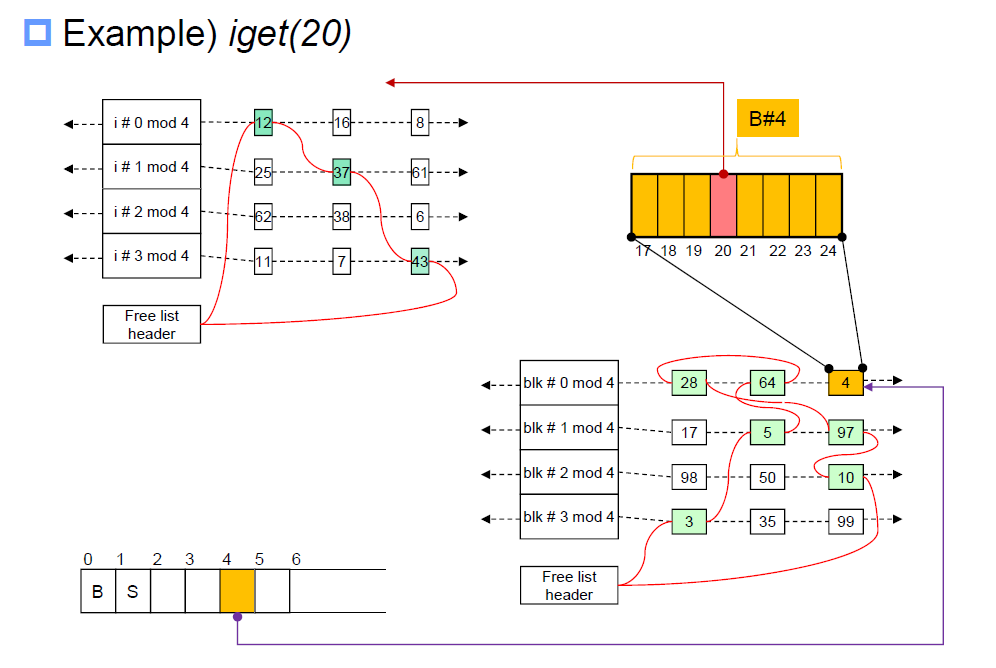
전체적인 system flow를 먼저 보겠습니다.
- 그림의 하단 왼쪽에는 disk에 있는 file subsystem이 block 단위로 나타나 있습니다. B는 boot block, S는 super block인데 각각 0번째 1번째 block을 차지하고 있습니다. 이후인 2번째 block 부터가 inode list 가 되고, inode list가 끝나면 이후부터는 data block이 오게 됩니다.
- 논리적인 흐름에 따른 다음 요소는 그림 오른쪽에 보이는 hash queue 와 free list 이며, 이는 buffer cache를 나타냅니다. Disk에서 block단위로 불러들여와진 부분 중 프로세스들이 필요한 부분만 메모리로 불러들여지는데, 메모리에 어떤 block이 위치하고 있는지, free 상태인지를 명시하고 있습니다. 결국은 inode도 file의 metadata이지만 엄연한 file이고, 메모리로 불러들여지는 과정은 buffer cache를 사용한다는 점을 인지해야 합니다.
- 그림 상단 오른쪽은 한 block에 대한 확대입니다. 한 block에 여러 개의 inode가 포함될 수 있음을 보이고 있습니다.
- 그림 상단 왼쪽은 hash queue와 free list로 설계된 inode table을 나타냅니다.
iget(20)을 호출하는 것은 20번 inode를 메모리로 불러들여와야 한다는 명령입니다. 위 시스템을 다시 보면 inode 번호를 주고 block number를 찾아야 하는데
modulus 4를 수행해 0이 나오므로 해당하는 hash queue를 들여다보고 4번 block이 있는것을 확인합니다.
iput() algorithm()
이제 inode를 release하는 방법에 대해 알아보겠습니다. In-core의 reference count를 1 감소시킨 다음 만약 0이라면 다른 file의 inode로 사용되어질 수도 있어 데이터가 지워질 가능성이 있으니 write back 후 free list에 걸어줍니다. Pseudocode에는 나와있지 않지만 reference count decrement는 atomic operation이어야 합니다. 그리고 free list로 거는 과정은 interrupt handling이 끼게 되어있습니다.

Reference count
마지막으로 inode에 동시에 존재하는 lock 과 reference count 개념에 대해 비교하고 넘어가겠습니다. 기본적으로 allocated inode에 대한 lock/unlock 은 reference count에 무관하게 실행할 수 있습니다.
| Inode lock | Reference Count |
| system call 수행되는 동안은 lock이 걸림. | 파일에 대한 참조가 하나씩 늘어날수록 reference count 또한 하나씩 늘어남. 즉, 파일 open 시 ++, 파일 close 시 -- |
| 한 system call과 다음 system call 사이에 lock이 걸려있을 수 없으며 무조건 풀려서 free 되어야 함. | system call 사이에 reference count는 변경되거나 없어지지 않음 (consistent). 이유는 active 한 in-core inode를 다시 reallocate 하지 못하게 하기 위함. |
Buffer cache의 자료구조 처리 알고리즘과 inode Cache(inode list) 처리 알고리즘에 대한 비교
| Buffer Cache | Inode Cache (Inode List) |
| getblk() buffer cache에 특정 buffer 할당 hash queue 와 free list 사용 lock 만 존재 |
iget() inode cache에 inode를 할당 hash queue 와 free list 사용 reference count free list management |
'CS > Operating Systems' 카테고리의 다른 글
| [Principles][4]File System(algorithms for allocation and freeing of file system resources) (0) | 2023.04.12 |
|---|---|
| [Principles][3]File System(locating files and data blocks) (0) | 2023.04.12 |
| [Principles][1]Buffer Cache (0) | 2023.03.26 |
| [Principles][0]General Summary (0) | 2023.03.21 |