Image courtesy of Prof. Young Ik Eom - SKKU

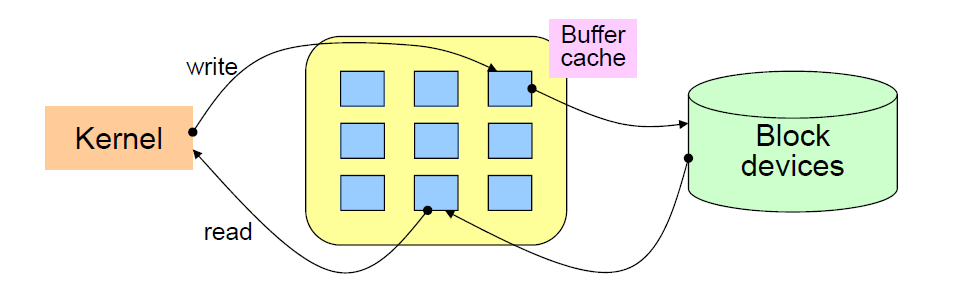
File subsystem 와 연결된 buffer cache (BC) 부터 시작해본다.

Theoretical Background
데이터가 cache에 있을 때는 disk read 를 하지 않고, cache에 없을 때 read 이후 caching 까지 진행한다. Writing 시 쓰여진 data 는 cache 된다.
그렇다면 Buffer 라는것은 어떻게 구성되어 있을까?
buffer = memory array + buffer header
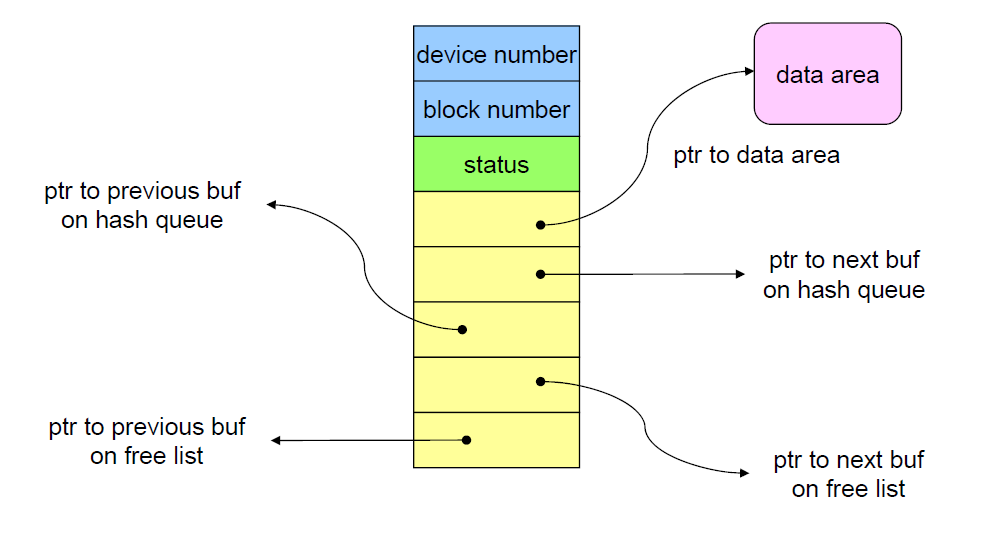
하나의 buffer 마다 1개의 헤더가 존재한다. Buffer header 안에는 device number, block number, buffer가 가진 정보로 갈 수 있는 pointer, current status, 그리고 hash queue와 free list 를 향하는 pointer가 있다.
모든 file system은 0, 1, 2 ... block sequence로 이루어져 있다. 그 중 몇 번 블록인지를 나타내는 것이 block number 이다. hash queue 의 경우, 어떤 kernel 의 file system 입장에서 보았을 때 x번 device의 y번 block을 가지고 있는 buffer가 있는지 buffer cache 안에 있는 모든 buffer들을 다 찾아봐야 한다. 이렇게 brute force 방식으로 모두 찾다보면 시간이 너무 오래 걸리기 때문에 device number 와 block number를 이용해 hashing 기법을 활용한다.
앞서 언급된 free list와 hash queue 는 buffer를 활용할 수 있도록 조건대로 나열해주는 자료구조이다.
Free List
먼저 free list부터 살펴본다. a. 어느 process도 buffer를 사용하고 있지 않은 경우 그 buffer는 free 상대로 marking 된다. b. free 상태로 marking된 buffer는 free list에 추가된다. c. 만일 특정 buffer를 어떤 process가 사용하는 중이라면 busy 상태로 marking 되며 free list에서 빠져나온다.
이것을 구현하기 위하여 doubly linked circular list가 활용되었으며 LRU algorithm에 의해 관리된다. 자료구조를 doubly linked circular list 를 사용한 이유는 문제에서 요구하는 점이 node insert / delete 하는 시간을 최소화하는 것이기 때문이다. 적절한 pointer만 주어지면 traverse 할 필요없이 constant time 안에서 insert/delete 할 수 있게 된다. Kernel은 buffer가 필요할 때 head 에서 떼어내고 return 할 때는 tail에 반납한다. 그러나 특별한 경우에는 LRU 원칙을 일관적으로 따르기 위해 free list의 head에 return 한다. 이 특별한 경우에 대해서는 나중에 시나리오적인 접근을 하며 더 알아본다.
Hash Queue
만약 kernel 에서 5번 device 12번 block을 찾으려고 한다면 이것을 찾으려고 할 때 모든 buffer를 방문해 헤더를 확인하기엔 너무 오래 걸리니, device number 와 block number 를 가지고 hasing 하는 hash queue 라는것을 사용한다고 하였다. 이는 buffer를 개별 queue로 정리하는 것이며 이렇게 하여 search space를 줄여 찾는 시간을 감소시킬 수 있다. 각각의 queue 는 free list와 같이 doubly linked circurlar list 를 활용한다. 여기서, hashing을 사용한다는 점에서 알 수 있겠지만 두 개의 buffer가 같은 disk block 의 정보를 가지고 있을 수 없다.
A Simplified Example
Free list와 buffer cache 자료구조가 어떻게 생겼는지 보여주는 예시입니다. 예시의 단순성을 위해 block number 로만 hashing 을 진행한다고 가정한다.

- Hash queue에 매달려 있으며 free list에도 동시에 매달려 있다면 해당 buffer contents 를 지금 어떤 application process도 사용하고 있지 않다는 뜻이다. 반대로, Hash queue에 매달려있으나 free list 에는 없다면 busy 상태임.
- Hash queue 에는 각각의 block device 의 device number와 block number를 modulus 연산해 해당되는 부분에 data 를 달아놓는다.
Scenario Study
Buffer cache를 가져오며, 나올 수 있는 시나리오에 대해 알아본다. 함수 이름은 getblk()

각 시나리오를 살펴보기 전에 기본이 되는 개념에 대해 알아본다.
Contention Issue
Sleep 후 wake up 되었을 때 'lock 이 풀렸으니 바로 buffer 써야지' 라고 생각하면 그것은 불가하다. 한 프로세스의 입장에서 보면, 이것이 sleep 되었을 때 다른 process가 buffer에 또 lock을 걸었을 수도 있고 buffer가 더 우선순위를 가지는 다른 프로세스에 의하여 사용되어 다른 storage data 를 가질 수도 있기 때문이다. 이를 contention issue 라고 한다. 따라서, wake up 된 상태에서는 바로 loop 처음으로 돌아가서 로직을 수행해야 한다.
Buffer Release
Buffer를 allocate 하는것은 system call execution 에 진행되고, system call return 이전에 release 된다. 시나리오를 들어가기 전에 buffer release 라는 것은 어떻게 하는지 알아본다. Unix에서 함수 이름은 brelse() 로 작성되어 있다. Lock이 걸린 buffer를 가져가 사용하다가 해당 buffer의 data가 더 이상 필요하지 않다면 buffer를 free list에 반납해야 한다.

위 파란색으로 쓰여진 부분들 사이에는 다른 system call 등으로 인하여 interrupt가 개입할 수 없는 (atomic) 부분이다. 이 부분에서는 free list에 enqueue 작업이 진행되는데, 만약 이 부분이 방해를 받으면 doubly linked list 중간에 완전 enqueue 가 끝나지 않은 상황에서 다른 프로세스에 의해 traverse 되어 치명적인 오류를 만들 수 있다. Interrupt가 개입할 수 없게 만드는 기법을 interrupt blocking 이라고 하는데 이것을 이루는 방법은 processor execution level을 높였다가 atomic operation이 끝나면 processor execution level을 낮추는 것이다.
+) getblk() 함수에서도 이러한 interrupt blocking은 전략적으로 사용됨.
Scenario 1: Block on the hash queue, and its buffer is free (the best case)
예를 들어, 다루고 있는 프로세스에서 4번 storage block data를 읽으려고 했는데 마침 4번 data가 buffer cache 안에 들어있고 free list 에도 포함이 되어있는 경우이다.
- 이 경우 buffer 를 free list에서 제거하고 busy로 marking 한다.
- Busy 상태로 바뀐 buffer에 대한 pointer는 getblk() 가 kernel로 리턴.
이것은 application 입장에서는 'cache hit' (컴퓨터구조론에서 다루는 것과 같은 컨셉) 에 해당하고 효율성 면에서 최고의 케이스로 볼 수 있다.

Scenario 2: Block not on the hash queue, so allocate a buffer from the free list
Hash queue에 없기 때문에 free list가 비었나 본 후, delayed write 찍여있지 않은 것을 확인한다. Delayed write 표시가 없으면 해당 buffer를 old hash queue (이전 device number, block number에 해당하는 hash 값)에서 dequeue 하고 new hash queue로 enqueue 한다.

Scenario 3: Block not on the hash queue, and finds "delayed write marked free block
특정 buffer가 free list에 있으며 delayed write 표시가 찍혀있다면, 다른 process가 이 buffer를 이전에 사용했던 것. 해당 buffer 내용은 storage에 async 방식으로 다시 쓰여져야 한다. Asynchronous 한 방식은 write 시켜놓고 끝날 때까지 기다리지 않는 것이다.
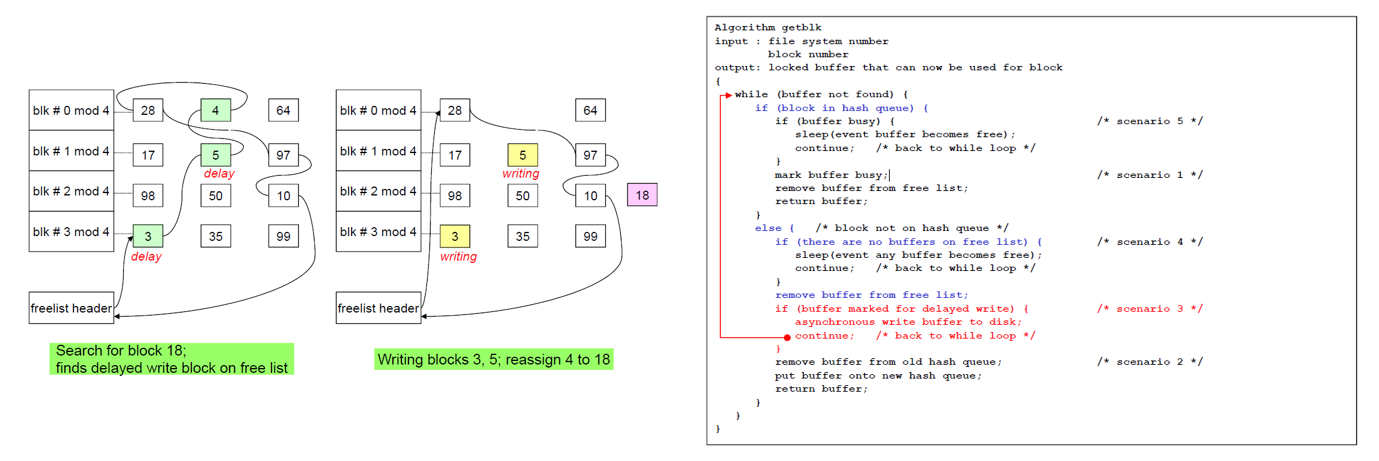
위 그림을 참고하면, 3번을 free list에서 떼내고 보니 delayed write 라서 block write 를 asynchronous 하게 진행하고 while 문 처음으로 다시 돌아간다. 5번으로 넘어갔을 때도 똑같은 상황이 발생한다. 이후 4번은 delayed write 표시가 없어, scenario 2번 scenario로 진행. 이 상황에서는 block number를 18번으로 바꾸고 old hash queue 에서 buffer를 제거하고 new hash queue로 enqueue 한다. 이 상태는 위치와 겉의 이름만 바뀐 상태로, 아직 block이 buffer에 읽혀 들어져온 상태는 아님.
Async write가 완료되면 free list에 매달아줘야 하는데 여기에서 LRU 알고리즘의 special case 가 고려되어야 한다. 만약 이 buffer를 free list의 tail에 또 매달면 이것은 tail에서 head까지 두 번을 traverse 하는 셈이 된다. 그것은 LRU policy에 맞지 않으므로 이 경우에는 head에 매달아야 한다.
Scenario 4: Block not on the hash queue, and free list is empty
Hash queue에도 free list에도 buffer cache가 없어 프로세스가 block release 함수인 brelse()를 호출할 때까지 기다려야 하는 상황이다. 여기에서 contention을 고려하여 sleep이 끝난다면 while loop 처음으로 돌아가야 한다.

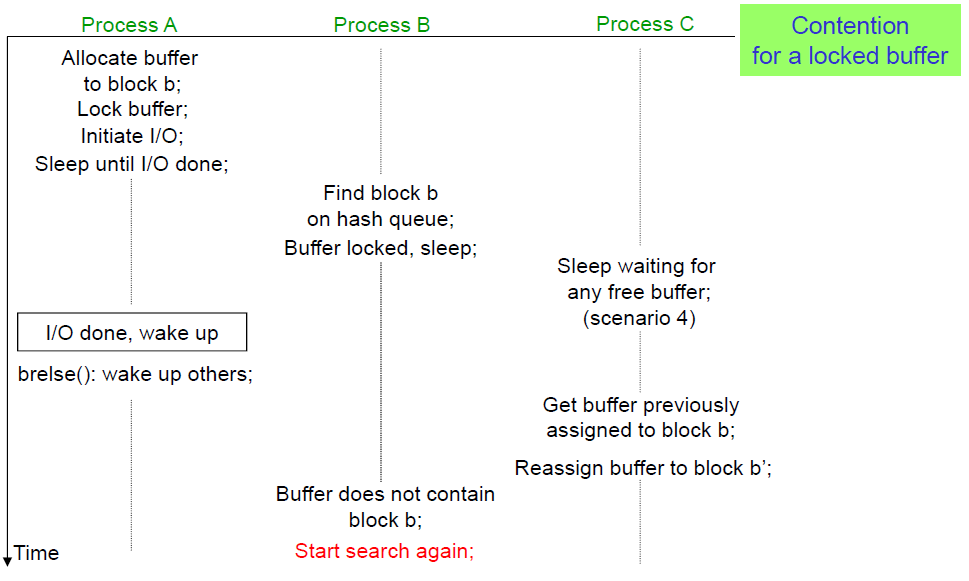
Contention이 발생하는 시나리오를 더 자세히 살펴보면 다음과 같다.
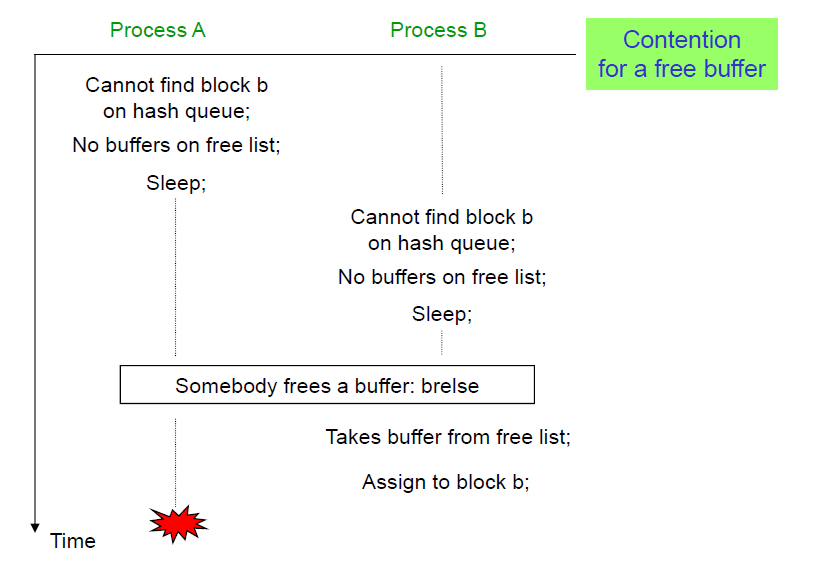
Process A와 B가 같은 이유로 sleep 되었는데, buffer release가 되고나서 process B가 buffer cache를 먼저 쟁취한다. While loop 처음부터 돌지 않았을 때를 가정하면, 같은 buffer를 노리는 process A는 buffer가 다른 process에 의해 사용되고 있기 때문에 crash가 날 것을 예상할 수 있다. 만약 contention issue를 피하기 위해 while loop 처음부터 돌았다면 free list에 있는 다른 buffer cache를 찾았을 것.
더 자세히 생각해보면 이 문제는 어떤 process가 sleep 을 깨어나서 바로 CPU를 scheduling 받아 실행한다는 보장이 없기 때문이다.
학부과정에서 배우는 process synchronization, mutual exclusion 개념과 synchronization 위한 여러 primitive 들인 semaphore, spin lock, read/write lock 등의 locking mechanism을 배우는 이유는 이 contention (또는 race condition) 이라고 하는 문제를 해결하기 위함이다. 이 문제가 발생하는 경우 같은 알고리즘을 여러번 돌려도 계속 다른 결과가 나오는 예측 불가능한 상황이 발생할 수 있다.
Scenario 5: Block on the hash queue, but its buffer is busy
Block이 hash queue에 있지만 busy state로 다른 프로세스에 의해 사용되는 경우에도 sleep 한다. Buffer cache 두 개가 모두 같은 block의 데이터를 담을 수 없다는 원칙을 지키기 위함이다.
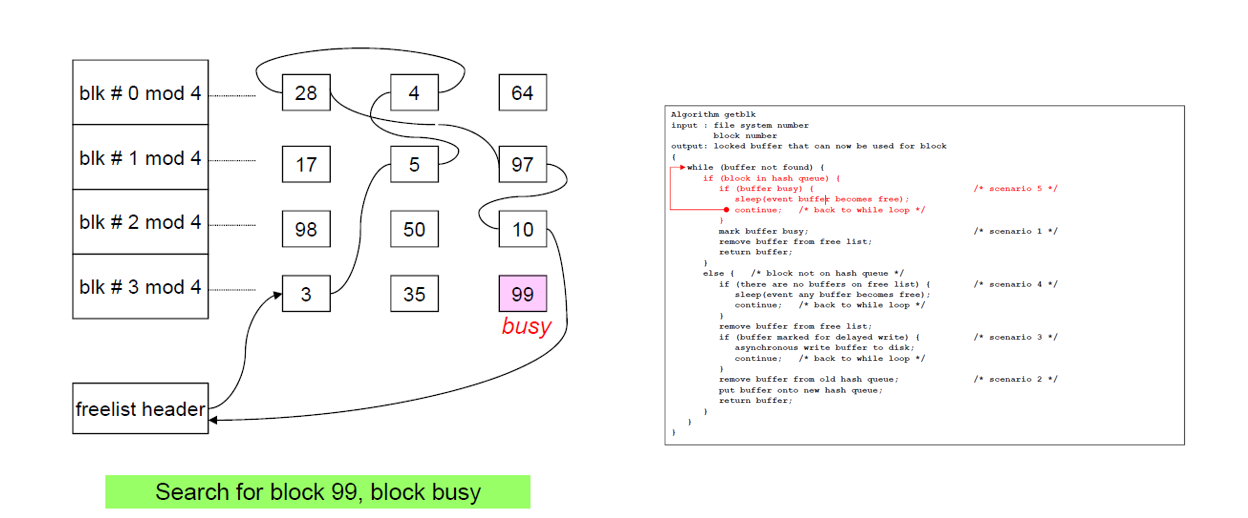
이렇게 진행될 경우 starvation이 발생할 확률은 있으나, buffer의 수가 매우 많기 때문에 적다.
getblk(), brelse() 를 호출하는 상위 알고리즘들
bread()
내가 원하는 데이터를 가지고 있다고 판단되는 buffer를 return.


- getblk() 호출
- buffer 하나 받아냄
- buffer의 contentes 가 valid 한 지를 확인 a. valid 하면 해당 buffer hash q 매달고 return 하고 나가기. b. disk로부터 해당 storage data 읽어 갖다넣은 다음 sleep. 깨어나면 validity 다시 검사 후 hash queue 매달고 return
breada()
연속적으로 데이터가 burst read 되어야 할 필요가 있는 경우 block read ahead 알고리즘이 사용된다. 첫 block 이 buffer cache 안에 있었는가 보고 두 번째 block은 disk read initiate까지는 하지만 async read 하여, read가 끝날 때까지 기다리지 않는다.

위 pseudocode 를 보며 오해가 생길 수 있는 부분은 if(first block not in cache), if(second block not in cache)인데, 사실은 첫 번째 block과 두 번째 block 모두 조건에 상관없이 getblk()를 호출해야 한다. 따라서 다음과 같이 변하는게 좋을 수 있겠다.
algorithm breada
input :
(1) file system block number for immediate read
(2) file system block number for asynchronous read
output :
buffer containing data for immediate read
{
get buffer for first block(algorithm getblk)
get buffer for second block(algorithm getblk)
if (first block not in cache){
if(buffer data not valid)
initiate disk read; // synchronous
}
// ...
}
bwrite()
Buffer cache에 있던 데이터를 block에 write 하는 알고리즘이다. 각 단계에 대해 설명하면 다음과 같은 순서이다.
- 어떤 프로세스가 buffer cache의 disk block data를 읽고는 write
- Delayed write mark 찍어놓는다. 이후 buffer가 release 되어 free list의 tail에 enqueue.
- Hard disk에 해당 buffer block의 원본 데이터가 있는데 거기에 write 시킨다. Buffer data를 storage에 가져다 쓰는 과정은 sync 일수도 async 일수도 있다.
Pseudocode로 살펴보겠습니다.

Synchronous write가 끝난 시점에서는 complete event를 받아 프로세스가 깨어난다. 이때 brelse() 는 왜 호출할까? 다시 복기해보면 brelse() 알고리즘은 (a) buffer를 필요로 할만한 모든 process에게 signal을 주고, (b) buffer를 free list(=doubly linked circular list)에 enqueue 한다. Buffer를 release 하는 이유는 write가 끝난 시점이니 해당 block number를 가진 block에 대한 데이터는 한동안 필요가 없음을 뜻할 것이다. 반면에 해당 buffer 자원은 필요하므로, buffer release 하여 free list에 매달아놓아야 한다.
이미 delayed write 라고 표시되어졌던 buffer를 write() 하는 경우에는 마지막 라인으로 오게 되는데, disk write 가 끝난 후 delayed write 에서 old 로 mark 가 변경된다..

이 알고리즘을 접할 때의 핵심은 write 에 세 가지 분류가 있다는 점.
- Synchronous write : Disk write 바로 시작, 끝날때까지 프로세스가 기다려줌
- Asynchronous write : Disk write를 바로 시작하긴 하지만 끝날때까지 프로세스가 기다려주진 않음
- Delayed Write : Physical block에 write 되는 시점을 최대한 미룸
Summary
여러 system call 간의 상호작용에서 buffer와 buffer management algorithm이 언제 동작하는지 더 넓은 범위에서 살펴보겠습니다. 아래 그림은 파란색 박스의 숫자 순서대로 진행되며 설명도 그에 맞추어져 있습니다. 여기서 write system call 과 bwrite()는 다른것임에 주의해야 합니다.
- A 라는 프로세스가 application level에서 데이터를 storage에 갖다 쓰라는 write system call을 호출합니다. 이것이 한 block 과 boundary alignment가 정확히 맞으면 그 block을 읽어들일 필요가 없지만 그렇지 않으면 buffer cache에 buffer data를 할당받아 그 block data를 읽어들여놓고 그 block data의 쓰고싶은 위치에 데이터를 씁니다. 이후 이것을 storage block에 다시 write 해야합니다. 이것은 궁극적으로 bread() 하여 block의 data를 읽어야 하고 그러는 와중 getblk() 도 호출이 됩니다. Write system call이 모두 끝나면 buffer release 를 하며 delayed write (dw) mark를 새겨놓고 free list의 tail에 enqueue 합니다.
- B 라는 프로세스가 read system call을 호출합니다. Block을 read하기 위해 getblk() 가 호출되고 읽고자 하는 disk block number가 buffer cache 안에 있는지 확인합니다. 원하는 데이터가 buffer cache 안에 들어있지 않아 free list에서 새로운 buffer를 할당받는데 delayed write mark가 찍혀있으니 bwrite()를 호출해 buffer의 데이터를 storage에 갖다씁니다. Buffer가 가지는 mark 도 delayed write 에서 old mark로 바꿉니다.
- Write가 끝나면 interrupt handler가 brelse() 하여 free list의 tail에 걸어놓습니다.

Buffer cache 를 사용하는 것이 장점만 있는것은 아니다. 아래의 테이블에서 장단점을 모두 정리해보았다.
Pros and Cons of Using Buffer Cache
| Pros | Cons |
| Uniform disk access : Data에 대한 locality가 강하더라도 storage data가 계속 읽히거나 쓰이지 않음. Storage 접근은 uniform하게 만들어주고, 여러 영역들을 골고루 접근할 수 있게 만들어주는 policy |
Vulnerable to crashes : 전원 공급이 안되던지 해서 꺼지면 작업하던게 다 날라간다. 이는 또한 system crash 발생가능성을 높여 reliability 문제를 발생시킨다. 특히 crash에 민감하게끔 만드는 요소가 delayed write 이다. 그럼에도 불구하고 Linux 와 Unix 는 모두 delayed write mechanism을 사용하고 있다. |
| More modular code : File system layer의 각종 function, system call layer의 각종 function 들과 연계해 modular 한 design이 나왔음. Modular 한 design은 코드의 유지보수에 도움. |
Requires extra data copy : 이건 어쩔 수 없다. |
| Simpler system design : | |
| No data alignment restrictions on user processes doing I/O : Modular design 덕이기도 하다. '1KB, 4KB boundary에 맞춰 읽어야 한다' 등의 제한을 두지 않게끔 해준다. System call layer 에서는 제한을 두지 않게끔 인터페이스를 제공하지만, file system internal로 내려오면 block boundary로 맞춰 data를 읽고 쓴다. |
|
| Reduction on disk traffic : 당연하겠죠? |
|
| File system integrity : |
지금까지 buffer cache 를 allocate, release 하는 getblk() 와 brelse() 알고리즘, 그리고 buffer로 disk의 데이터를 쓰는 bread() buffer의 데이터를 disk로 가져다가 쓰는 bwrite() 알고리즘에 대해 살펴보았다. 이 단원을 마무리하면서 얻어가야 할 핵심은 '어떤 scenario' 가 와도 buffer cache 가 어떻게 동작할 지를 아는 것' 이 되겠다.
다음 글부터는 Unix file system (UFS) 를 다뤄보겠다.
'CS > Operating Systems' 카테고리의 다른 글
| [Principles][4]File System(algorithms for allocation and freeing of file system resources) (0) | 2023.04.12 |
|---|---|
| [Principles][3]File System(locating files and data blocks) (0) | 2023.04.12 |
| [Principles][2]File System(algorithms for in-core inode) (0) | 2023.04.11 |
| [Principles][0]General Summary (0) | 2023.03.21 |